







































russtedrake PRO
Roboticist at MIT and TRI
Part 1: Introduction
Nur Muhammad
"Mahi" Shafiullah
New York University
Siyuan Feng
Toyota Research
Institute
Lerrel Pinto
New York University
Russ Tedrake
MIT, Toyota Research Institute
Imitation Learning
Behavior Cloning (BC)
Inverse Reinforcement Learning (IRL)
Today: BC of end-to-end (visuomotor) policies, with a bias for manipulation
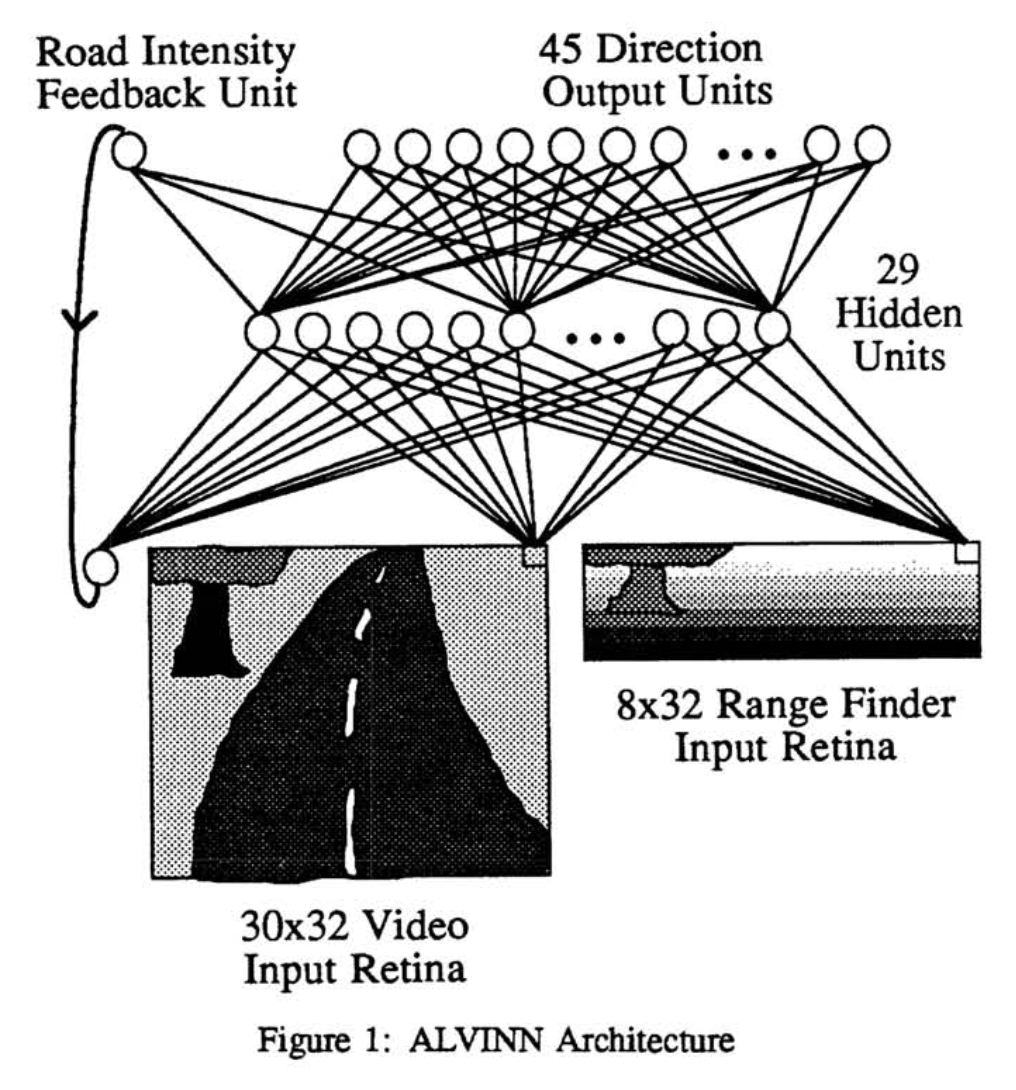
NeurIPS 1988
Teacher-student distillation
"Offline RL as weighted BC"
* - heavily dependent on task complexity/test diversity
At the banquet dinner this Wednesday I got asked...
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
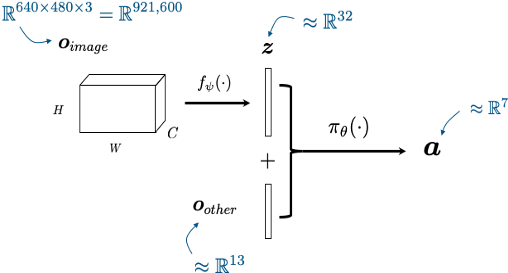
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history
large language models
visually-conditioned language models
large behavior models
\(\sim\) VLA (vision-language-action)
\(\sim\) EFM (embodied foundation model)
TRI's LBM division is hiring!
Why actions (for dexterous manipulation) could be different:
should we expect similar generalization / scaling-laws?
Success in (single-task) behavior cloning suggests that these are not blockers
Andy Zeng's MIT CSL Seminar, April 4, 2022
Andy's slides.com presentation
Big data
Big transfer
Small data
No transfer
robot teleop
(the "transfer learning bet")
Open-X
simulation rollouts
novel devices
Pete Florence, Corey Linch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrien Wong, Johnny Lee, Igor Mordatch, Jonathan Thompson
https://rail.eecs.berkeley.edu/deeprlcourse
proposed fix: DAgger (Dataset Aggregation)
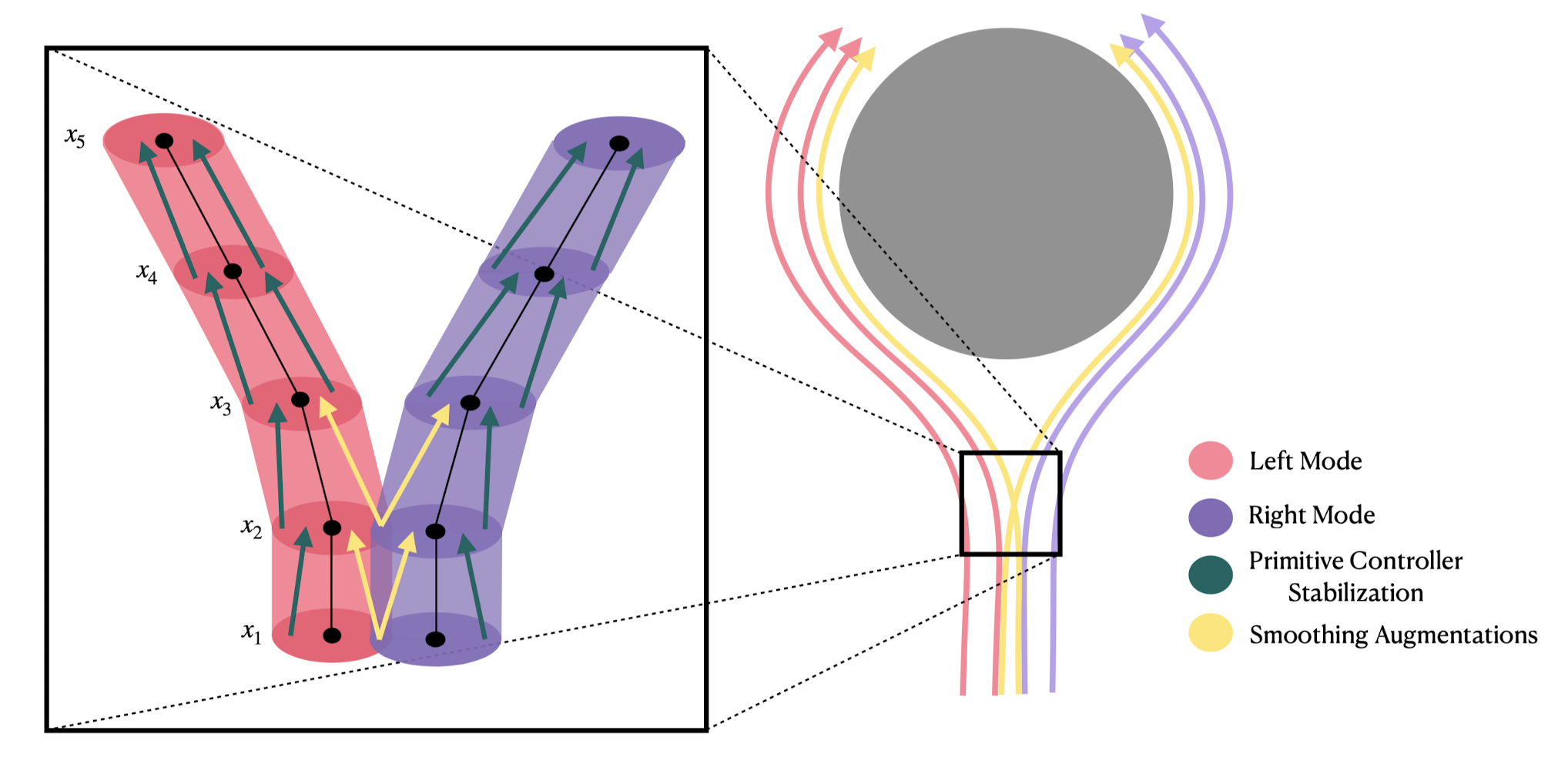
Provable Guarantees for Generative Behavior Cloning: Bridging Low-Level Stability and High-Level Behavior.
Adam Block*, Ali Jadbabaie, Daniel Pfrommer*, Max Simchowitz*, Russ Tedrake. NeurIPS, 2023.
A simple taxonomy
input
output
Control Policy
(as a dynamical system)
Most models today are (almost) auto-regressive (ARX):
As opposed to, for instance, state-space models like LSTM.
\(H\) is the length of the history
Transformer
input encoder(s)
output decoder(s)
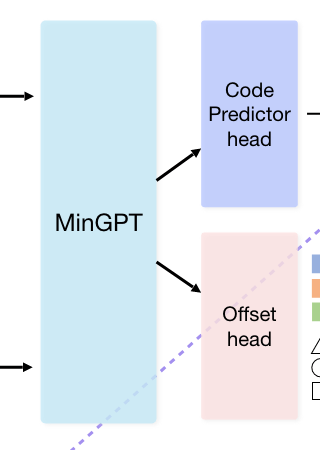
"each action dimension in RT-1/2(X) is discretized into 256 bins [...] uniformly distributed within the bounds of each variable."
Open source reproduction:
https://openvla.github.io/
Robotics Transformer (RT)
[...]
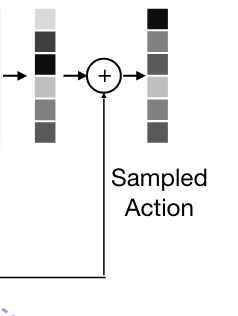
Behavior Transformer (BeT)
Action-chunking Transformer (ACT)
https://aloha-2.github.io/
"Overall, we found the CVAE objective to be essential in learning precise tasks from human demonstrations."
but I'm pretty sure people sometimes turn the CVAE off.
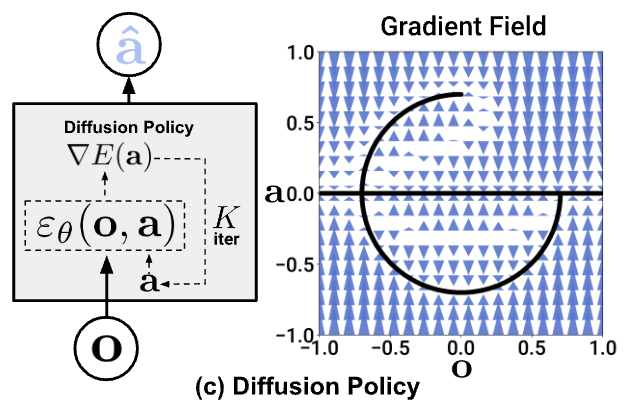
Diffusion Policy (DP)
Learning categorial distributions already worked well (e.g. AlphaGo, GPT, RT-style)
BeT/ACT/Diffusion helped extend this to high-dimensional continuous trajectories
\(H\) is the length of the history,
\(P\) is the length of the prediction
Almost certainly, but first I want to understand...
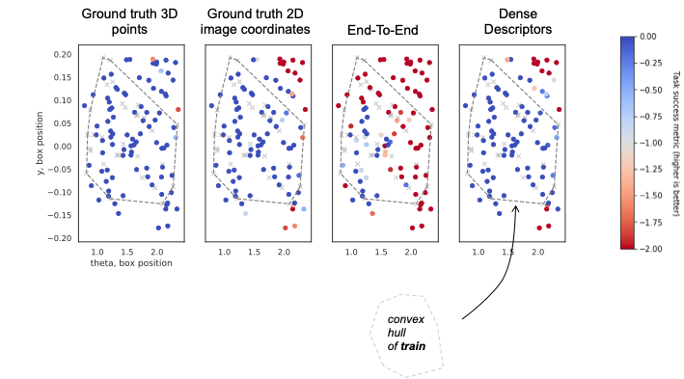
I really like the way Cheng et al reported the initial conditions in the UMI paper.
At TRI, we have non-experts run regular "hardware evals"
w/ Hadas Kress-Gazit, Naveen Kuppuswamy, ...
w/ Hadas Kress-Gazit, Naveen Kuppuswamy, ...
Example: we asked the robot to make a salad...
(Establishing faith in)
python lerobot/scripts/visualize_dataset.py \
--repo-id russtedrake/tri-small-BimanualStackPlatesOnTableFromTable \
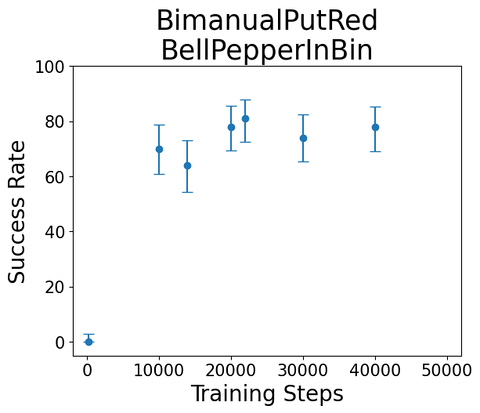
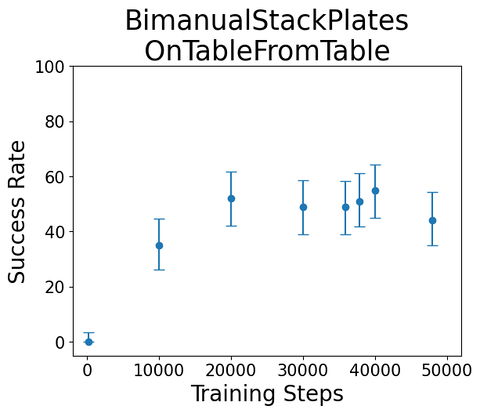
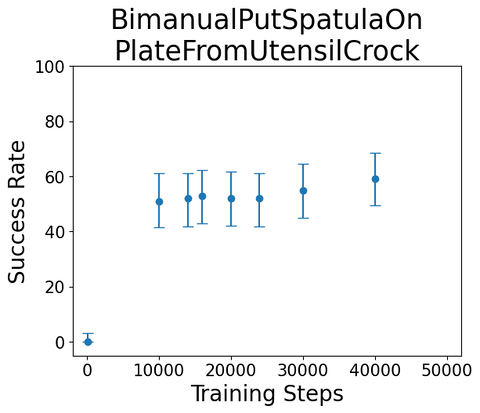
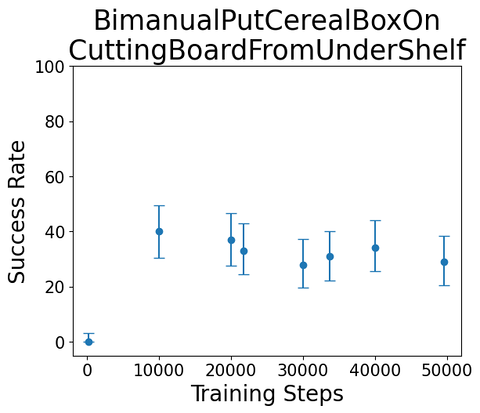
--episode-index 1We trained some single-skill diffusion policy on these skills; here are some example roll-outs/scores
Task:
"Bimanual Put Red Bell Pepper in Bin"
Sample rollout from single-skill diffusion policy, trained on sim teleop
Task:
"Bimanual stack plates on table from table"
Sample rollout from single-skill diffusion policy, trained on sim teleop
lbm_eval
from lbm_eval import evaluate
result = evaluate(
my_policy, only_run={"put_spatula_in_utensil_crock": [81]}
)def evaluate(
policy: Policy,
only_run: Optional[Dict[ScenarioName, List[ScenarioIndex]]] = None,
t_max: Optional[float | Dict[ScenarioName, float]] = None,
output_directory: str = None,
use_eval_seed=True,
) -> MultiEvaluationResult:
"""Evaluate a manipulation policy.
Evaluates the policy `policy` on the whole evaluation corpus or,
alternatively, only those scenarios and instances named in `only_run`.
Each policy is run for `t_max` time, or less if the policy succeeds early.
If `t_max` is unspecified, then the default value for each scenario is
used.
Any logging or other files generated by the evaluations will be saved
in `output_directory`.
"""Dale McConcachie, TRI
(100 rollouts each, \(\alpha = 0.05\))
to be remembered, if not used
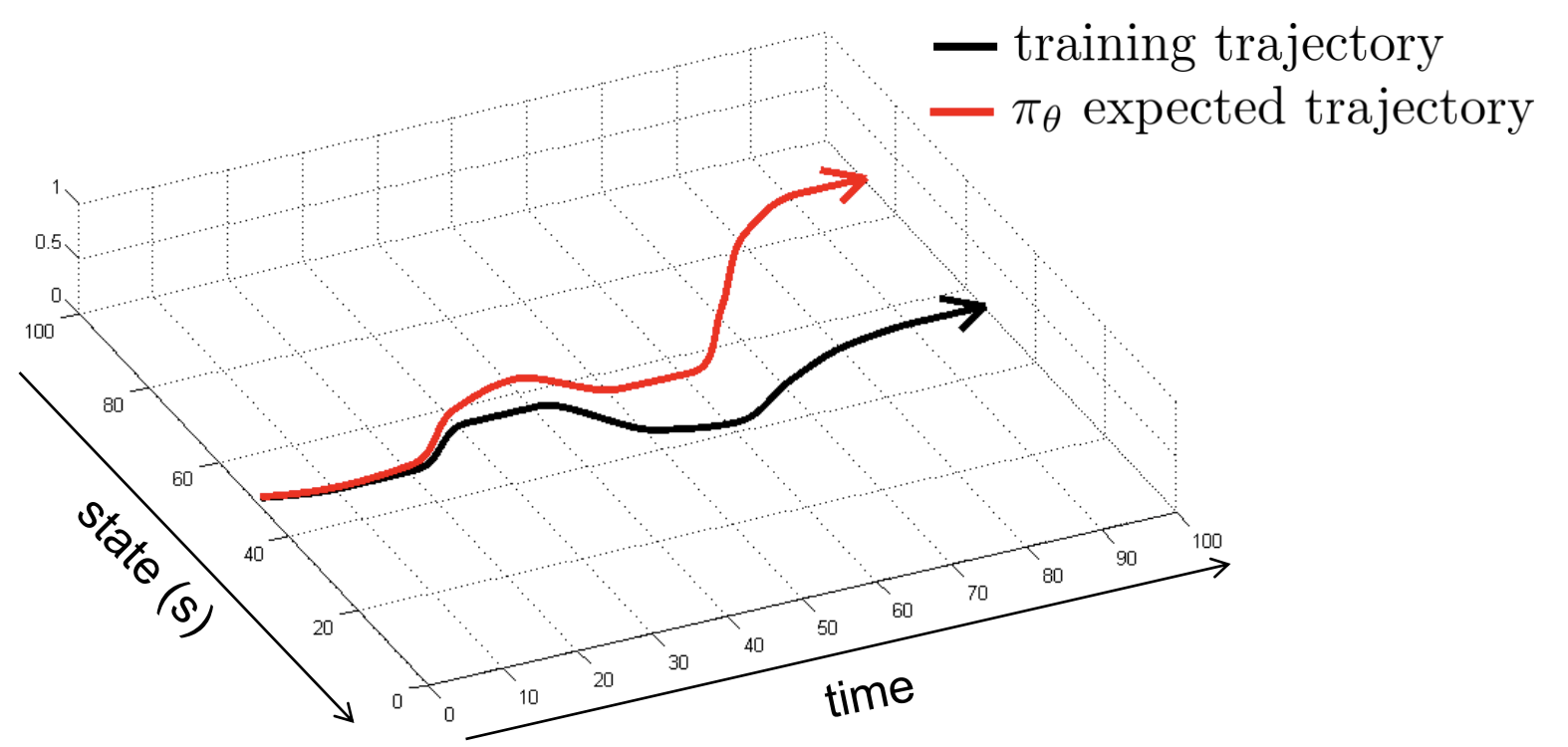
Thought experiment:
To predict future actions, must learn
dynamics model
task-relevant
demonstrator policy
dynamics
w/ Chenfanfu Jiang
NVIDIA is starting to support Drake (and MuJoCo):
By russtedrake



