









russtedrake PRO
Roboticist at MIT and TRI
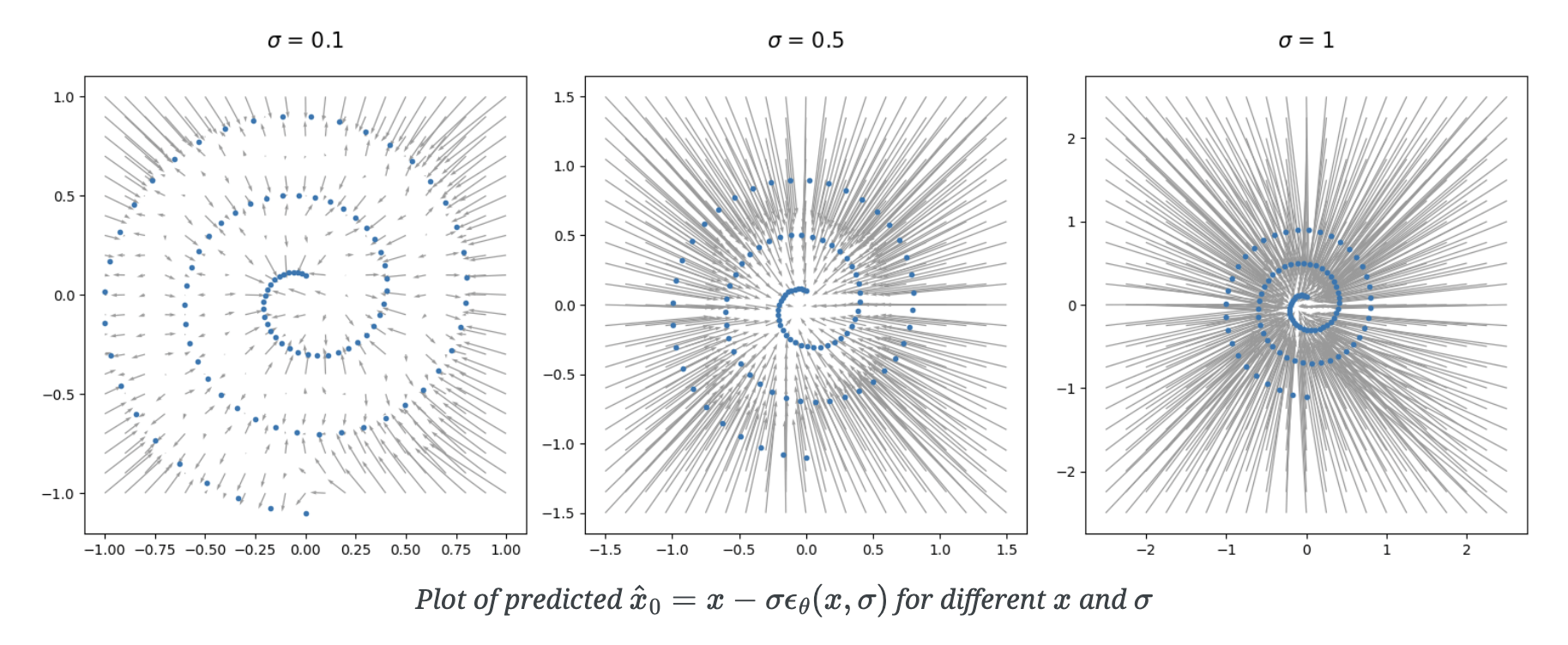
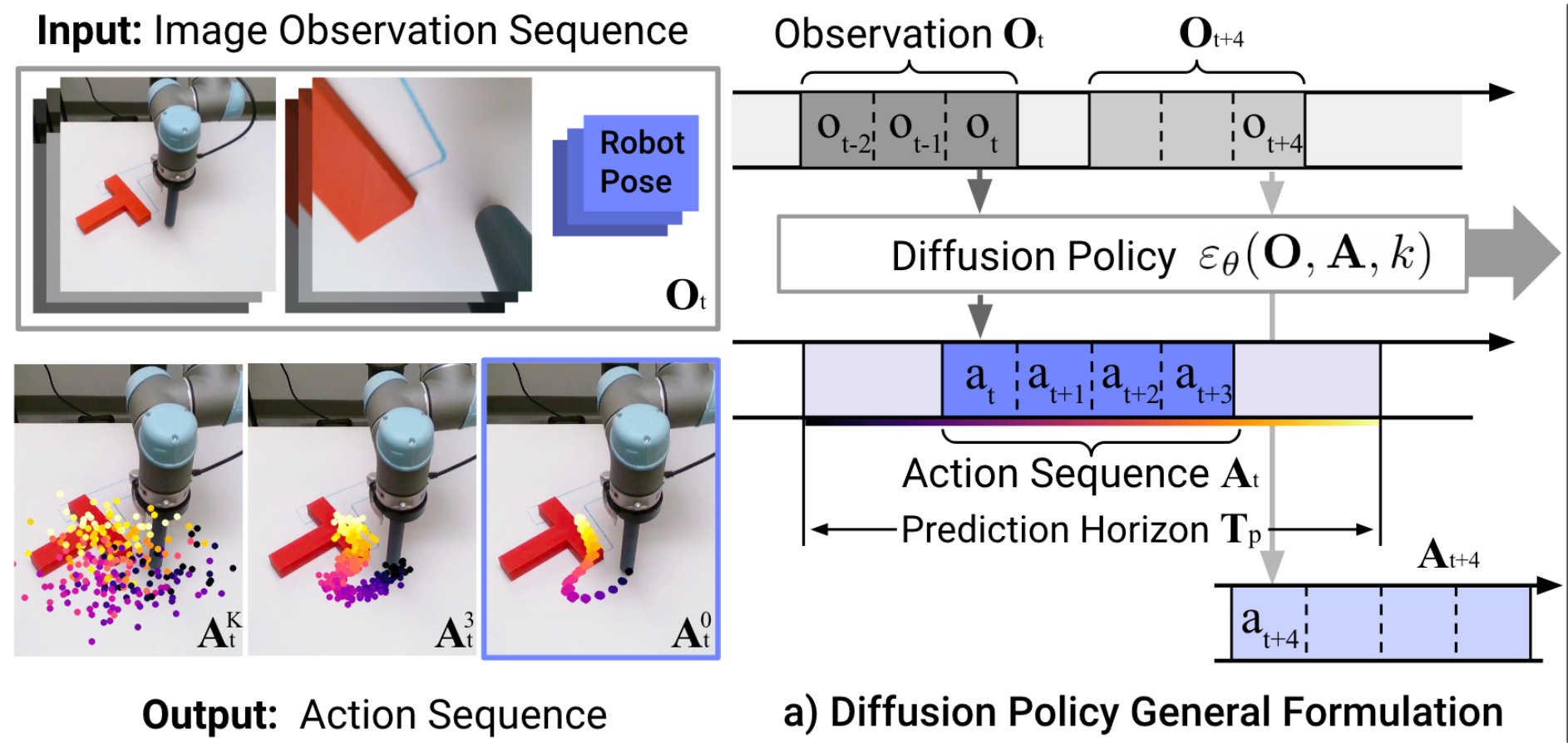
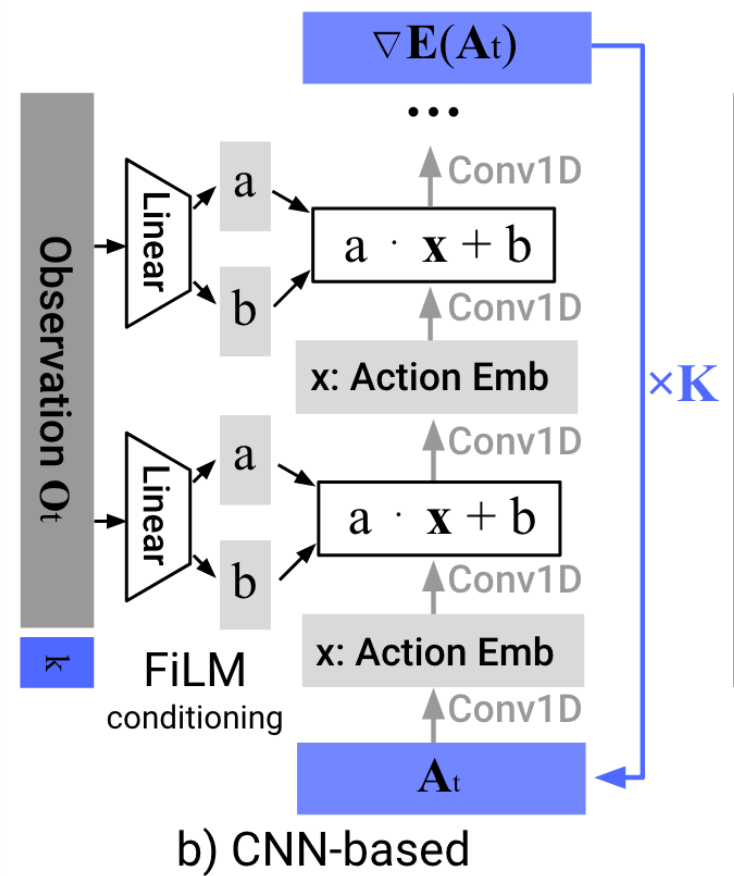
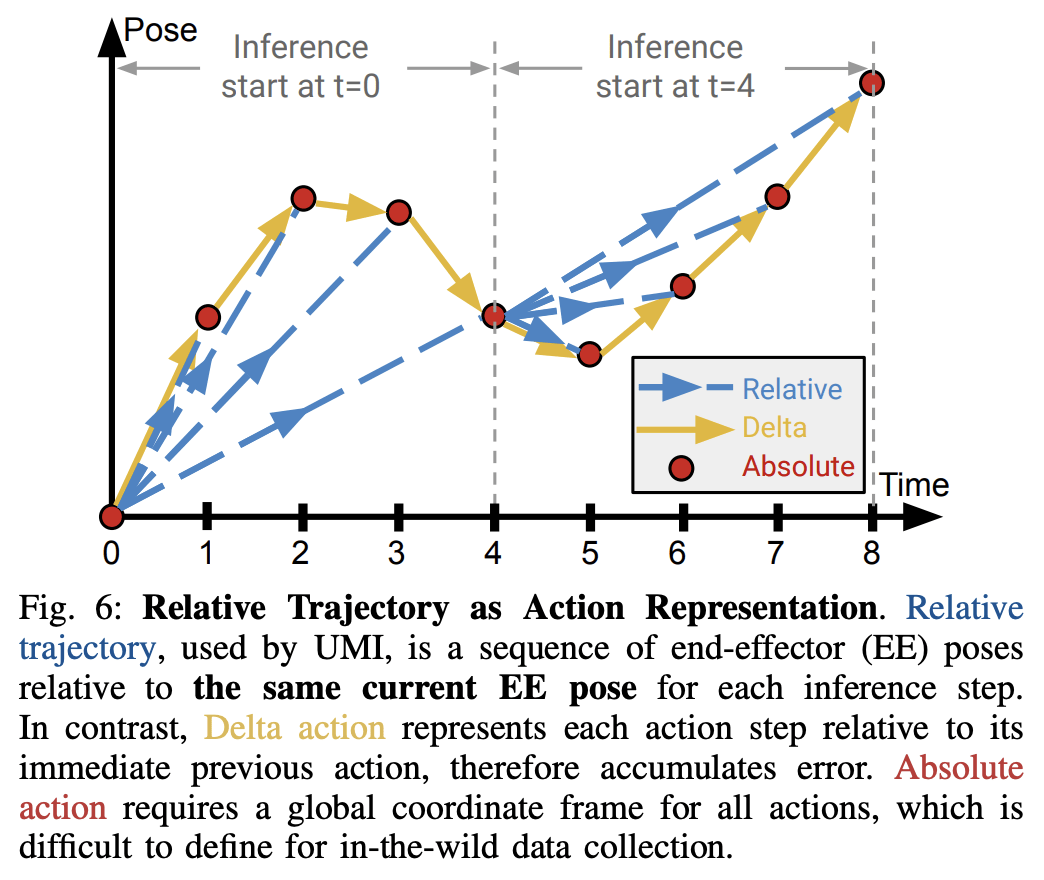
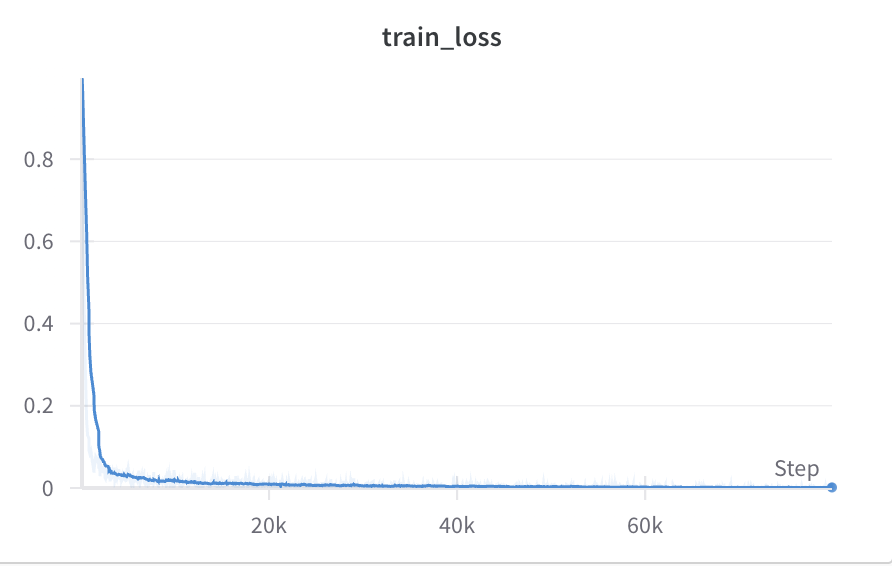
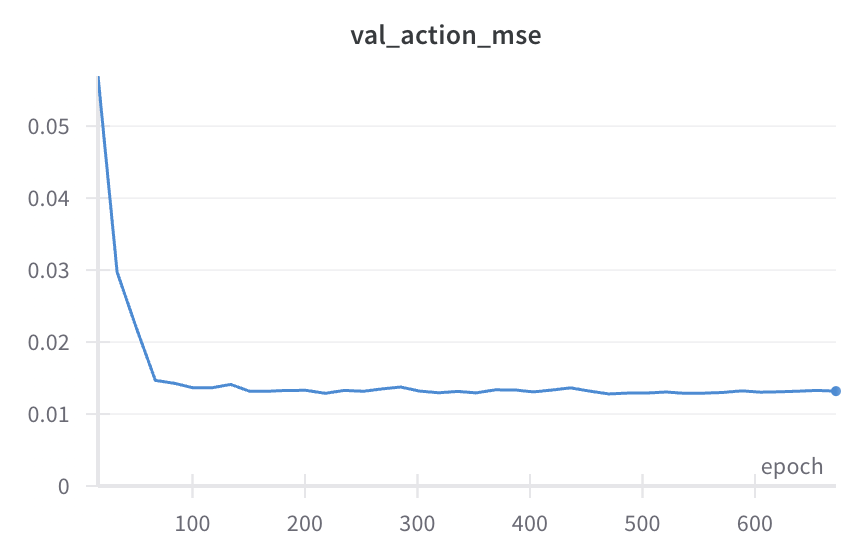
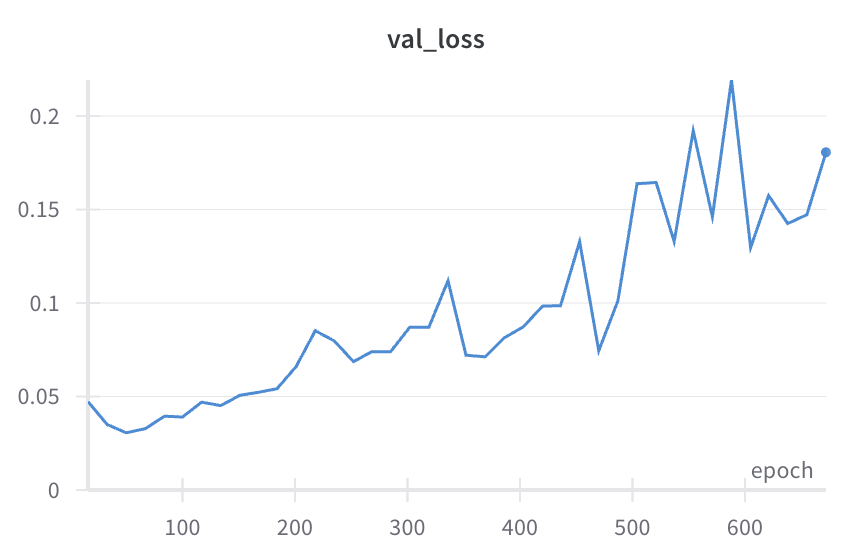
Diffusion Policy Deeper Dive
Nur Muhammad
"Mahi" Shafiullah
New York University
Siyuan Feng
Toyota Research
Institute
Lerrel Pinto
New York University
Russ Tedrake
MIT, Toyota Research Institute
great tutorial: https://chenyang.co/diffusion.html
another nice reference:
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
(when training a single skill)
(we've now trained many hundreds)
interestingly, seems even more important in sim.
w/ Chelsea Finn and Sergey Levine
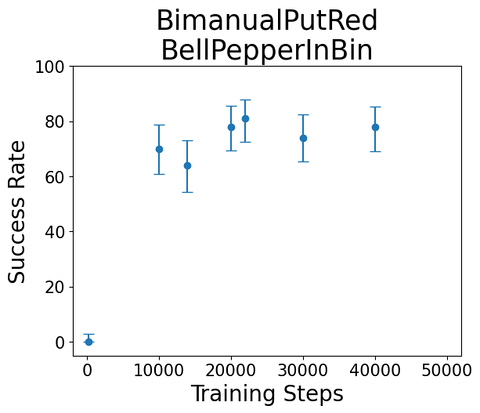
Compared to many datasets, these are long-horizon (often 30 seconds - 1.5 minutes)
Often sequential/multistep
Q: So how many demonstrations do I need to get to 99.99% success rate (\(\Rightarrow\) a useful product)?
My Answer: That's not the question I want to answer.
I want "common sense robustness" (from multitask), then will re-examine.
lbm_eval gives us the tool we needed
with TRI's Soft Bubble Gripper
Open source:
----------------------------------------------------------------------------------------------
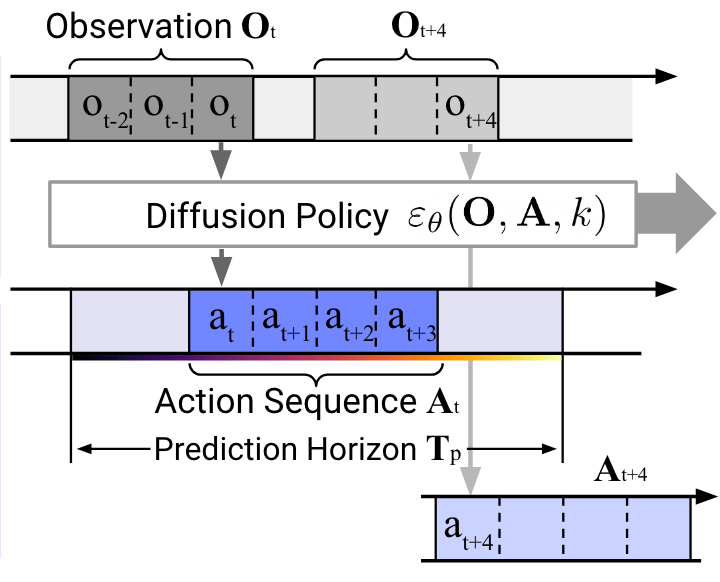
(legend: o = n_obs_steps, h = horizon, a = n_action_steps)
|timestep | n-o+1 | n-o+2 | ..... | n | ..... | n+a-1 | n+a | ..... |n-o+1+h|
|observation is used | YES | YES | YES | NO | NO | NO | NO | NO | NO |
|action is generated | YES | YES | YES | YES | YES | YES | YES | YES | YES |
|action is used | NO | NO | NO | YES | YES | YES | NO | NO | NO |
----------------------------------------------------------------------------------------------(that's almost what our code does, too)
nicely documented in lerobot
but it's never really been tested for o > 2
By russtedrake



