






russtedrake PRO
Roboticist at MIT and TRI
(Part 2)
MIT 6.421:
Robotic Manipulation
Fall 2023, Lecture 20
Follow live at https://slides.com/d/HoT1aag/live
(or later at https://slides.com/russtedrake/fall23-lec20)
Do Differentiable Simulators Give Better Policy Gradients?
H. J. Terry Suh and Max Simchowitz and Kaiqing Zhang and Russ Tedrake
ICML 2022
Available at: https://arxiv.org/abs/2202.00817
vs
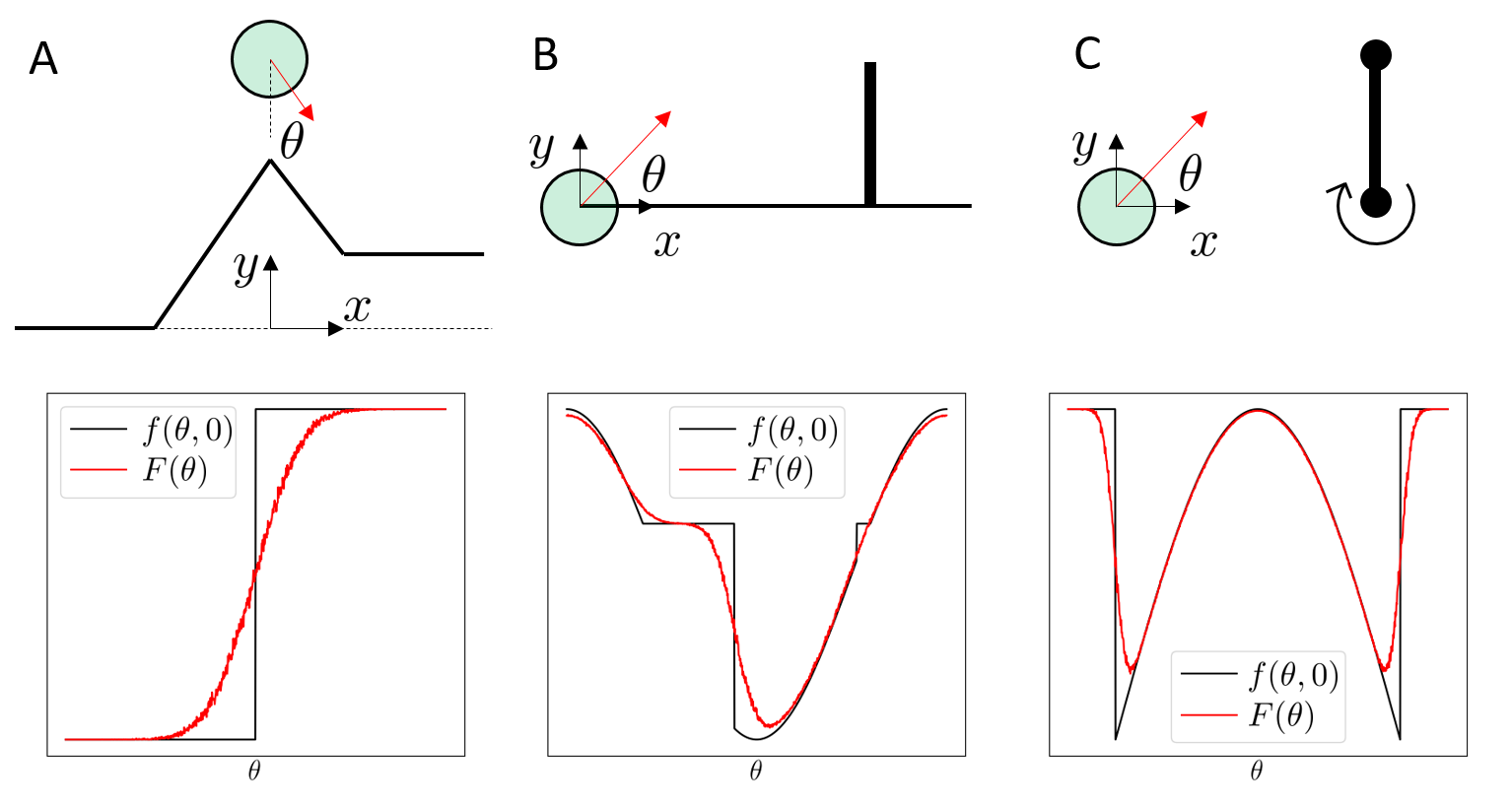
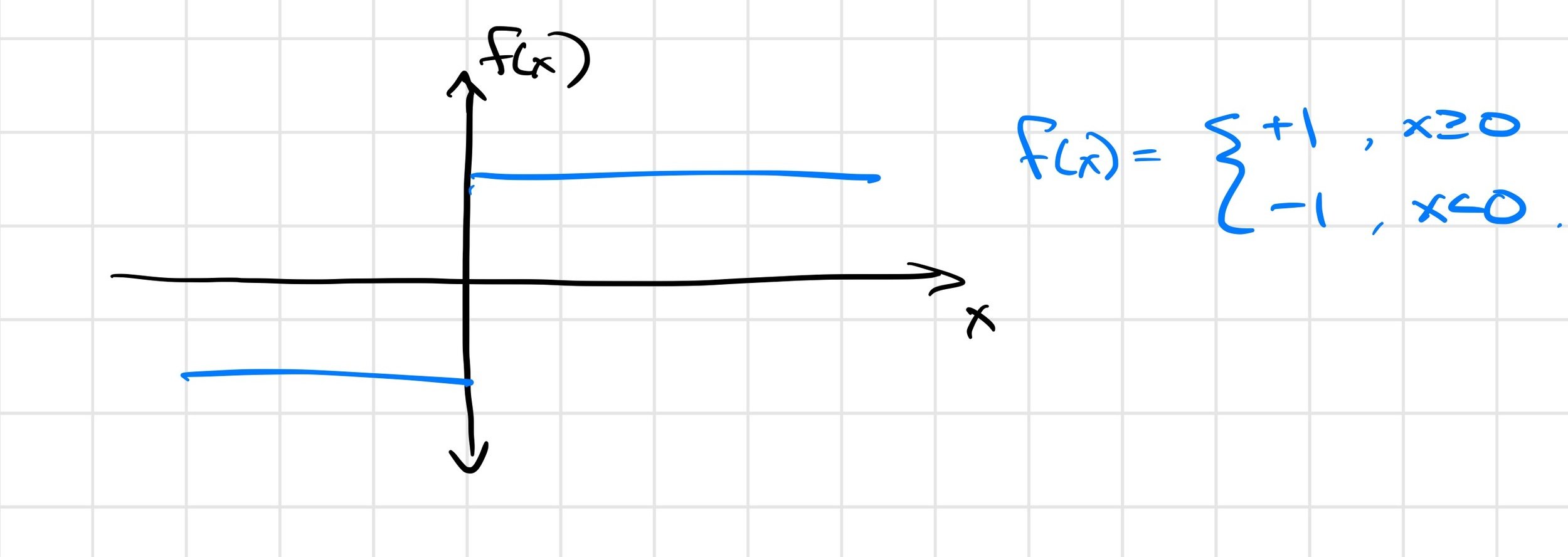
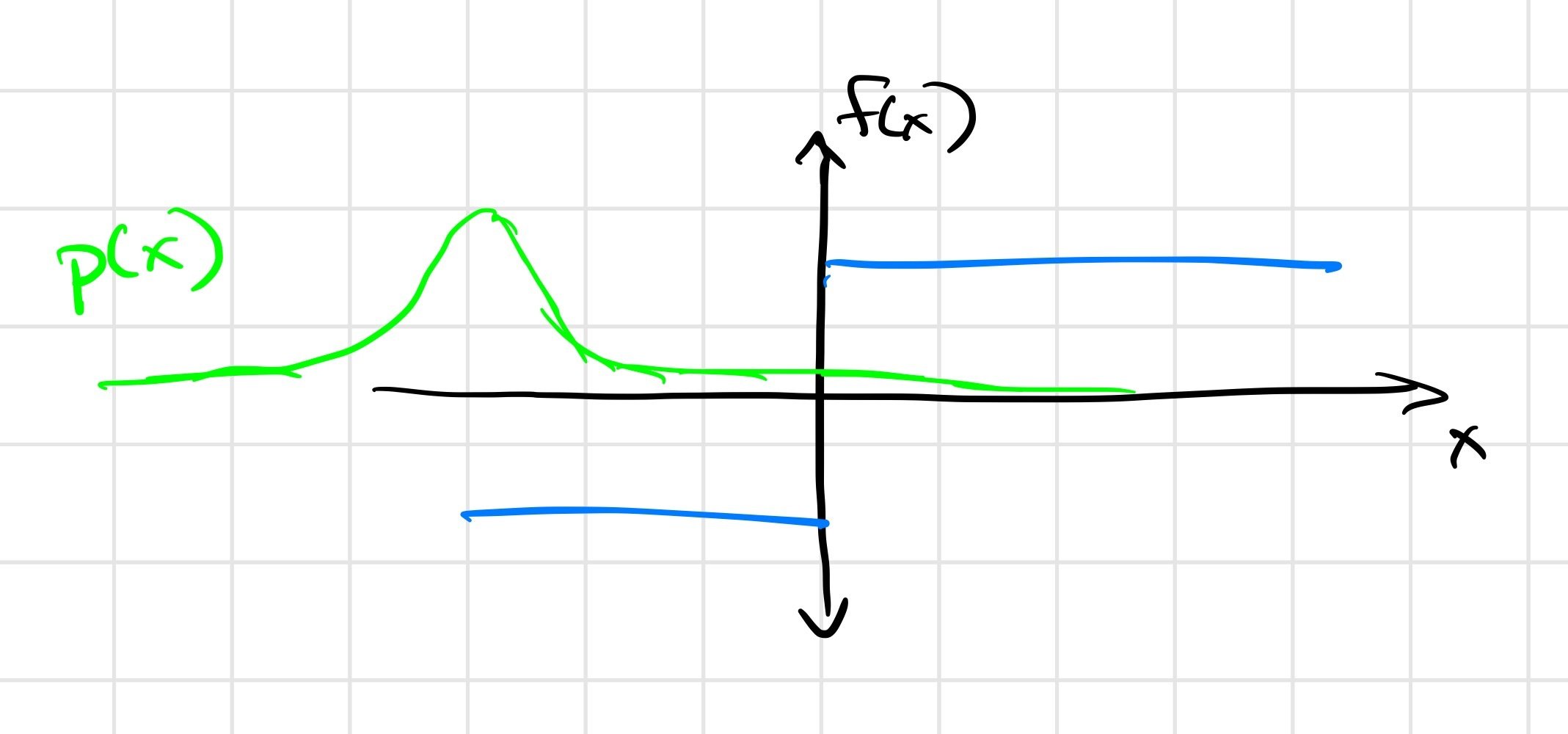
The answer is subtle; the Heaviside example might shed some light.
vs
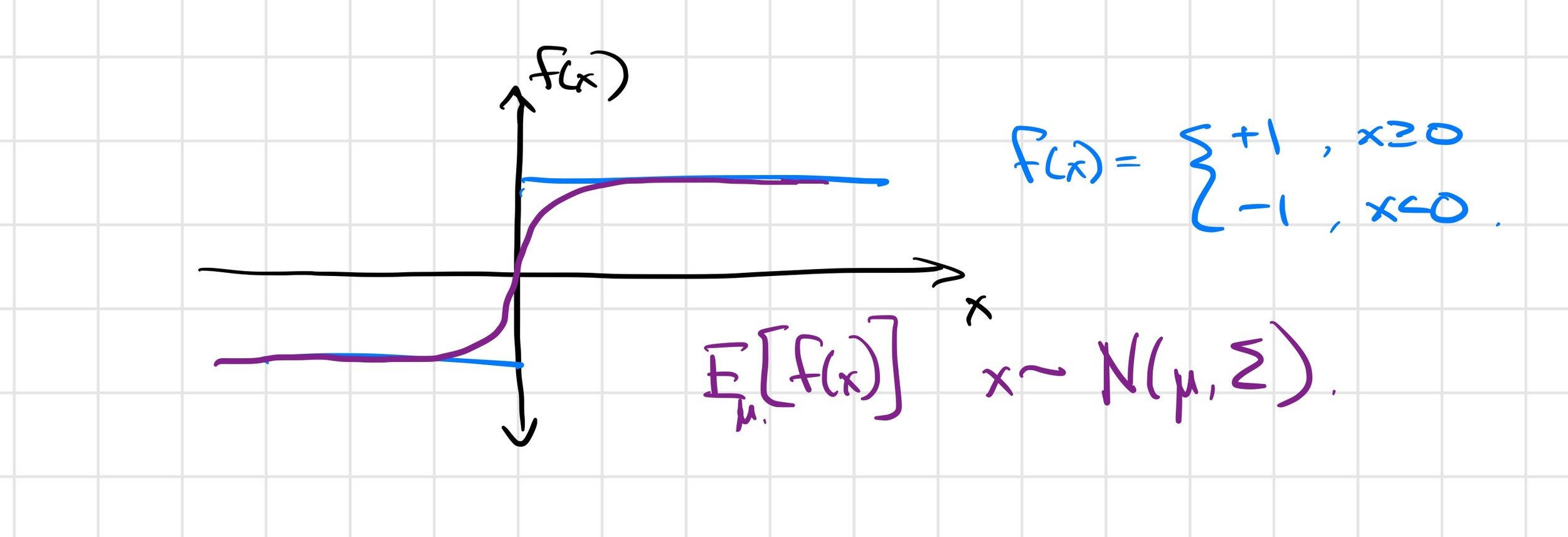
Differentiable simulators give \(\frac{\partial f}{\partial \theta}\), but we want \(\frac{\partial}{\partial \theta} E_w[f(\theta, w)]\).
J. Burke, F. E. Curtis, A. Lewis, M. Overton, and L. Simoes, Gradient Sampling Methods for Nonsmooth Optimization, 02 2020, pp. 201–225.
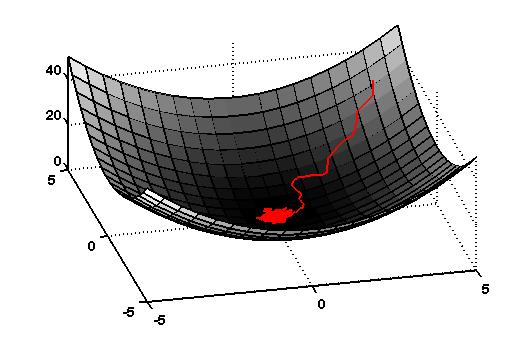
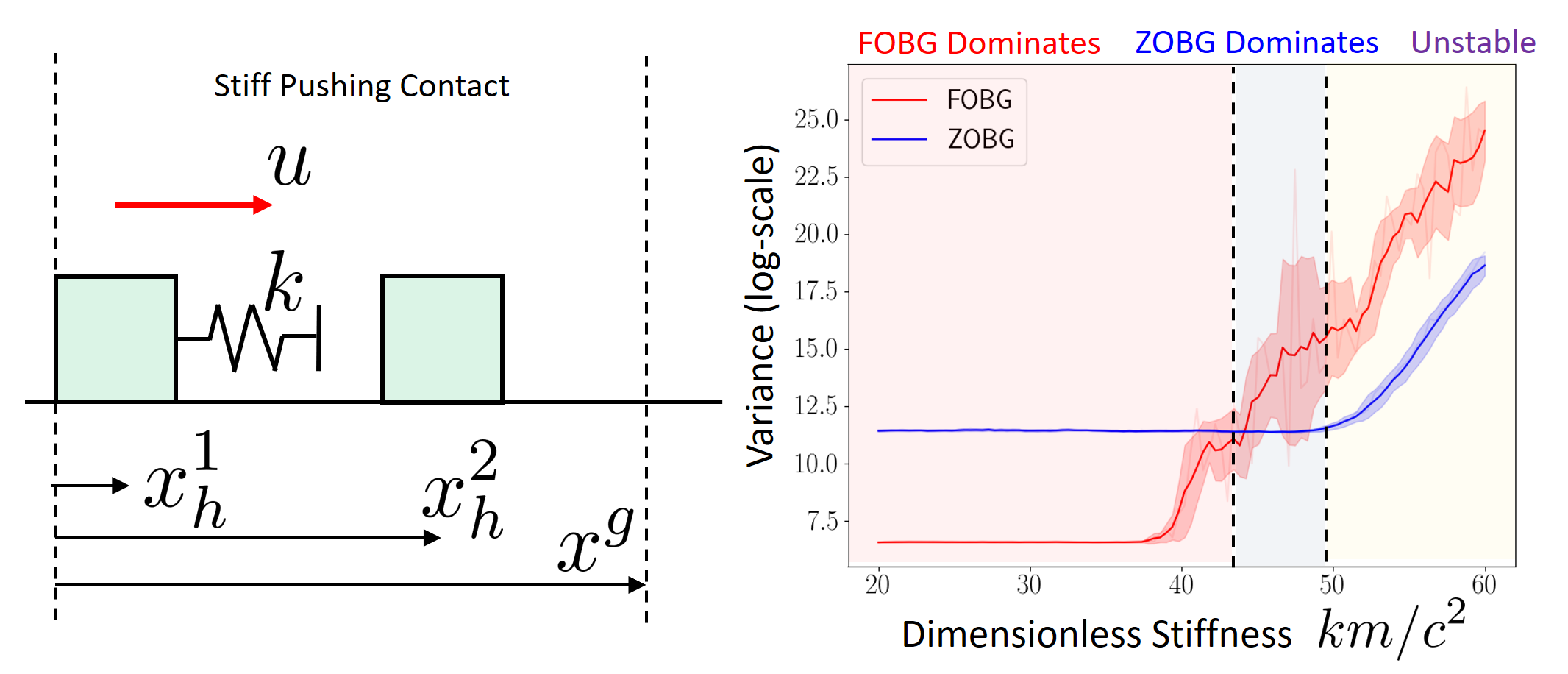
But the regularity conditions aren't met in contact discontinuities, leading to a biased first-order estimator.
Often, but not always.
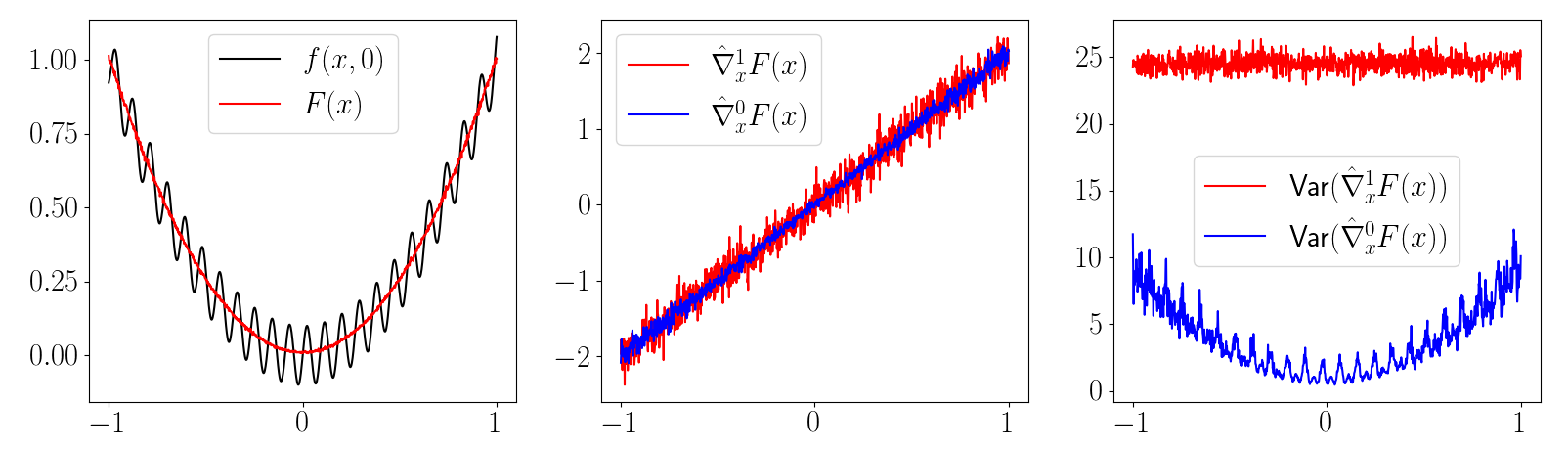
\(\frac{\partial f(x)}{\partial x} = 0\) almost everywhere!
\( \Rightarrow \frac{1}{K} \sum_{i=1}^K \frac{\partial f(\mu + w_i)}{\partial \mu} = 0 \)
First-order estimator is biased
\( \not\approx \frac{\partial}{\partial \mu} E_\mu [f(x)] \)
Zero-order estimator is (still) unbiased
e.g. with stiff contact models (large gradient \(\Rightarrow\) high variance)
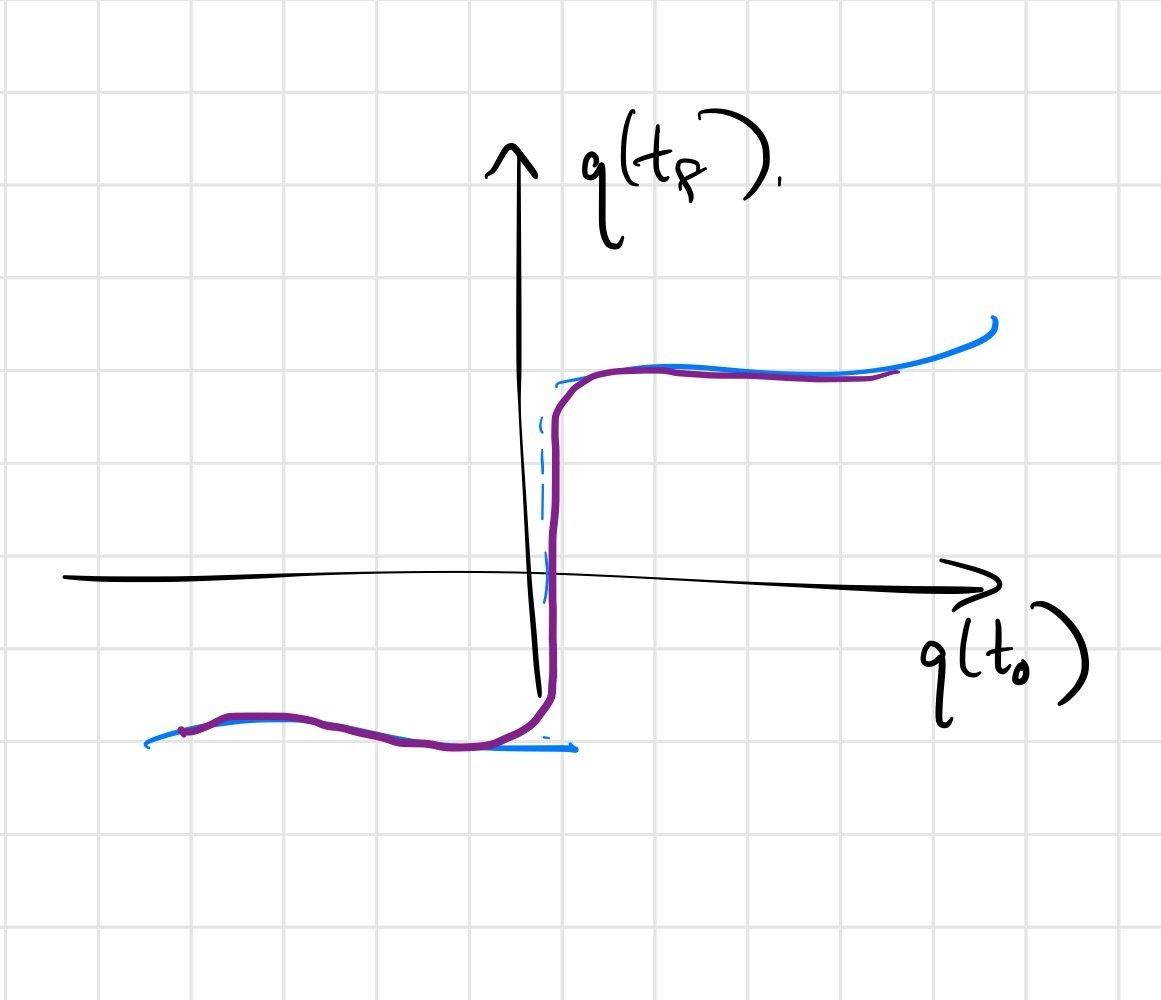
Global Planning for Contact-Rich Manipulation via
Local Smoothing of Quasi-dynamic Contact Models
Tao Pang, H. J. Terry Suh, Lujie Yang, and Russ Tedrake
Available at: https://arxiv.org/abs/2206.10787
Establish equivalence between randomized smoothing and a (deterministic/differentiable) force-at-a-distance contact model.
By russtedrake
MIT Robotic Manipulation Fall 2023 http://manipulation.csail.mit.edu


