










russtedrake PRO
Roboticist at MIT and TRI
(Part 1)
MIT 6.421:
Robotic Manipulation
Fall 2023, Lecture 19
Follow live at https://slides.com/d/HoT1aag/live
(or later at https://slides.com/russtedrake/fall23-lec19)
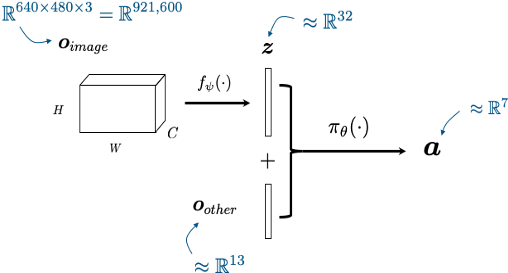
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
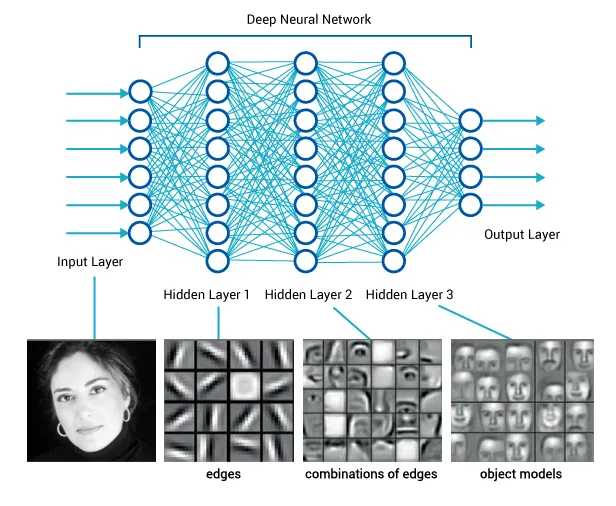
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history
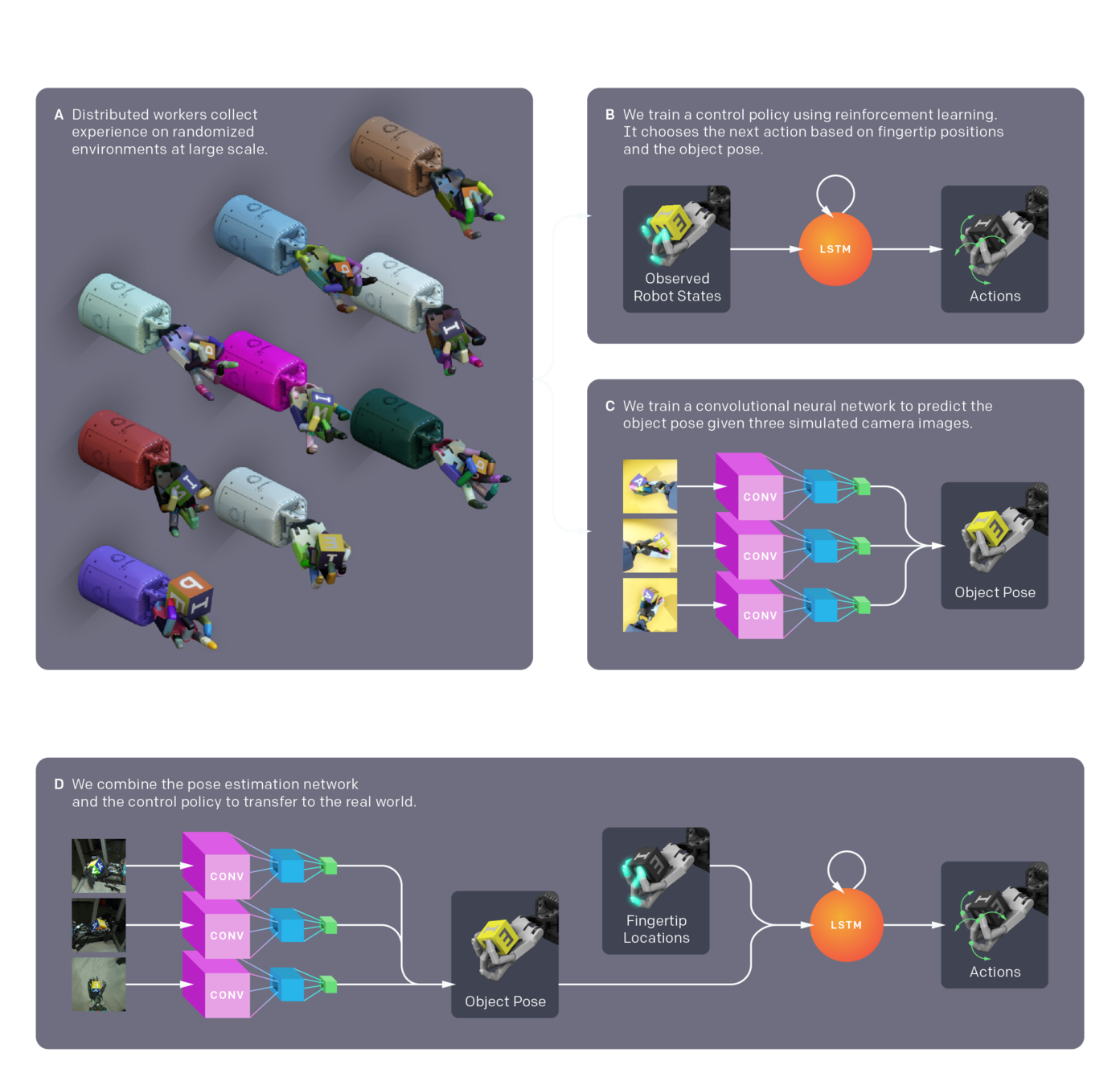
OpenAI - Learning Dexterity
Recipe:
import gymnasium as gym
class FooEnv(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
...
def step(self, action):
...
def reset(self):
...
def render(self, mode='human'):
...
def close(self):
...https://gymnasium.farama.org/
import pydrake.all
builder = DiagramBuilder()
....
diagram = builder.Build()
simulator = Simulator(diagram)
simulator.AdvanceTo(...)
observation = sensor_output_port->Eval(context)
reward = reward_output_port->Eval(context)
context = diagram.CreateDefaultContext()
meshcat.Publish(context)from pydrake.gym import DrakeGymEnvLee et al., Learning quadrupedal locomotion over challenging terrain, Science Robotics, 2020
OpenAI - Learning Dexterity
"PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance."
https://openai.com/blog/openai-baselines-ppo/
model = PPO('MlpPolicy', env, verbose=1, tensorboard_log=log)
stable_baselines3/common/policies.py#L435-L440
# Default network architecture, from stable-baselines
net_arch = [dict(pi=[64, 64], vf=[64, 64])]Actions
Observations
builder.ExportOutput(inv_dynamics.get_desired_position(), "actions")Network
builder.ExportOutput(plant.get_state_output_port(), "observations")approximately:
angle_from_vertical = (box_state[2] % np.pi) - np.pi / 2
cost = 2 * angle_from_vertical**2 # box angle
cost += 0.1 * box_state[5]**2 # box velocity
effort = actions - finger_state[:2]
cost += 0.1 * effort.dot(effort) # effort
# finger velocity
cost += 0.1 * finger_state[2:].dot(finger_state[2:])
# Add 10 to make rewards positive (to avoid rewarding simulator
# crashes).
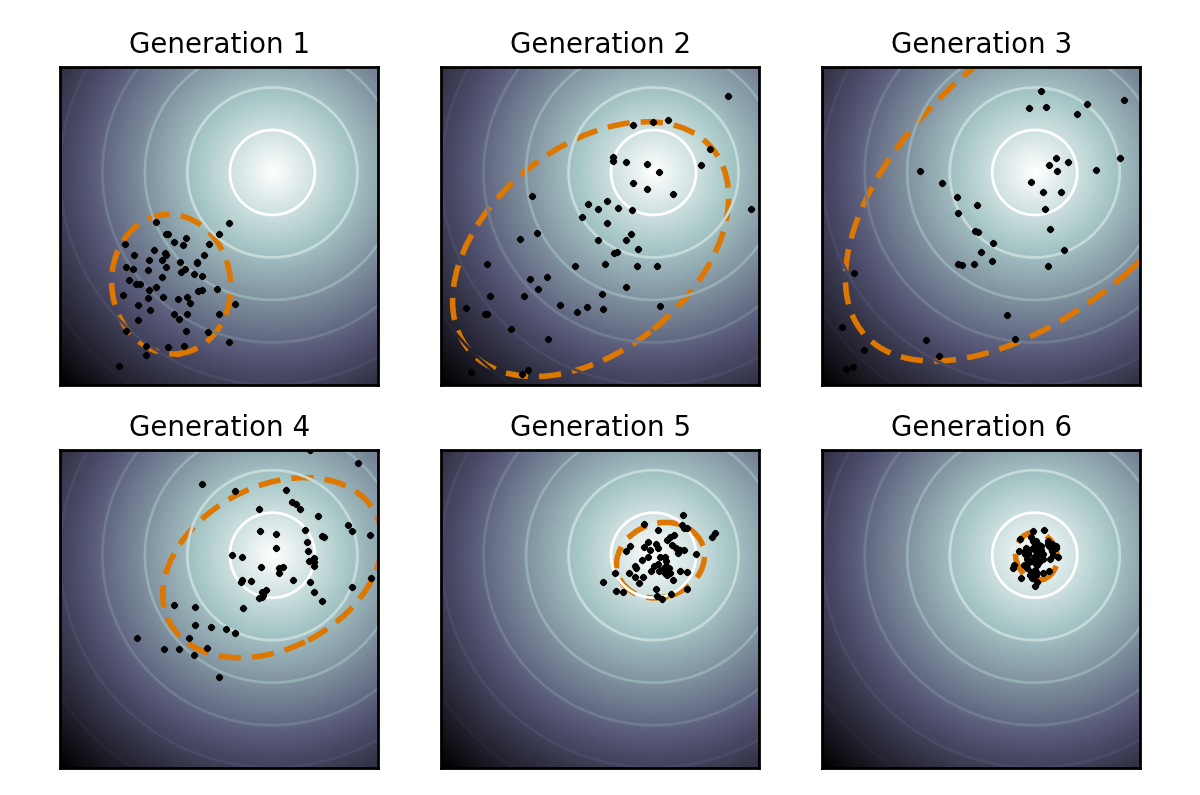
output[0] = 10 - costhttps://en.wikipedia.org/wiki/CMA-ES
(Image source: Tobin et al, 2017)
Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
https://spinningup.openai.com/en/latest/algorithms/ppo.html
By russtedrake
MIT Robotic Manipulation Fall 2023 http://manipulation.csail.mit.edu


