How to deploy and scale an ML model in production using



- Freelance Senior Data Scientist (currently at Servier)
- +7 years experience in Consulting, Tech, and Startups
- Interests in NLP, MLOps, and AI products
- ML trainer
- Content creator on Medium
Ahmed BESBES
Follow me on




What we'll learn today
This presentation will cover:
- APIs and production machine learning
- BentoML: an Open Source Model Serving framework
- Overview of ML-related features
- Demo
- Resources to go further

Don't hesitate to interrupt and ask questions!

Terminology
A model: a parametrized function whose weights (or parameters) are learned from data. Example: a logistic regression or ... a neural network
Model training: the step where the model weights are learned (or adjusted) from data by through the optimization of an cost function
Model inference: the step where the trained model predicts on new (unseen) data
1. APIs and production machine learning
Because there's a life after jupyter notebooks
What happens when your model is done training?
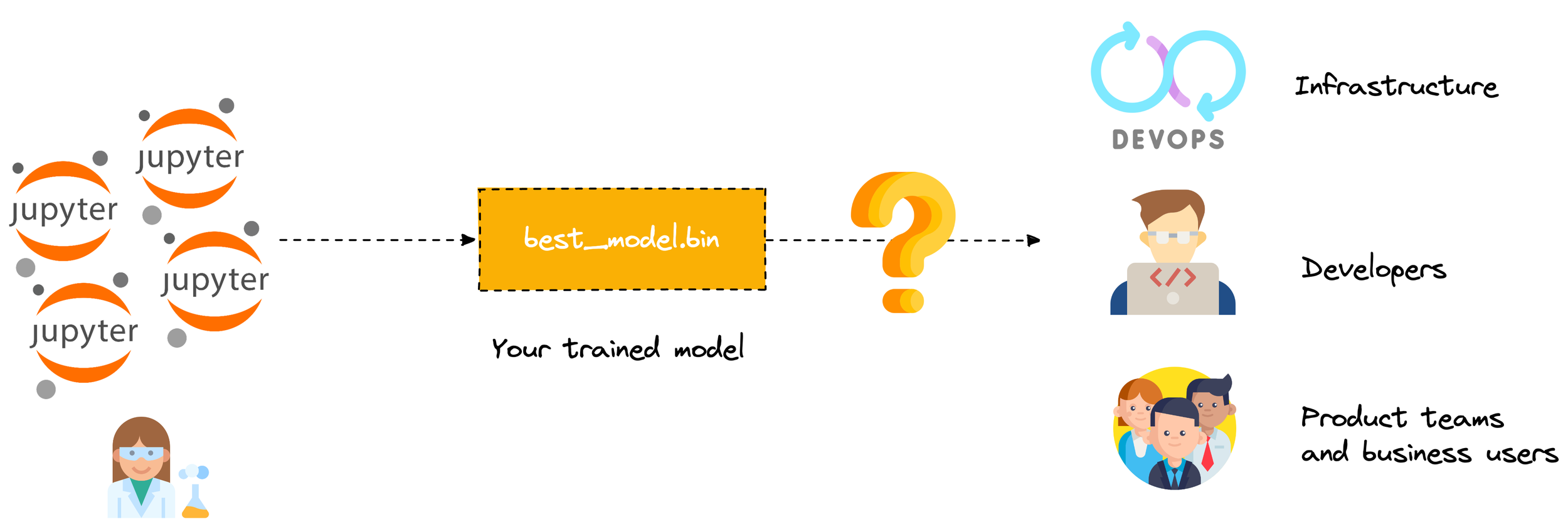
An after-life
- The infra team needs a minimum of code packaging and dependency management to deploy your model
- DevOps needs to know about resource consumption
- Business and product teams need to stress-test the model (i.e. API needs to scale to multiple concurrent queries)
- Developers need to access your API documentation to know how to consume it
API Requirements
As a data scientist, you want
- Support for multiple frameworks (torch, TF, scikit learn)
- Micro batching
- Performance and scalability: parallelization, high throughput
- Ability to use accelerated runtimes (GPUs)
As a thoughtful colleague, you want
- Reproducibility
- Dependency management
- Documentation
- Monitoring
- Debugging
- Data validation
2. BentoML

Open Source Model Serving
- Simplifies model serving and deployment
- Packages everything you need in a distribution format called a bento
- Enables data science agility
- Integrates Pre/Post processing
- Supports many popular ML frameworks
- Automatically generates Docker container
- Deploy to any cloud infrastructure
- Improves the inference performance

A Bento is like Docker container, but for ML
Bento is a file archive with all the source code, models, data files, and dependency configurations required for running a user-defined bentoml.Service, packaged into a standardized format.
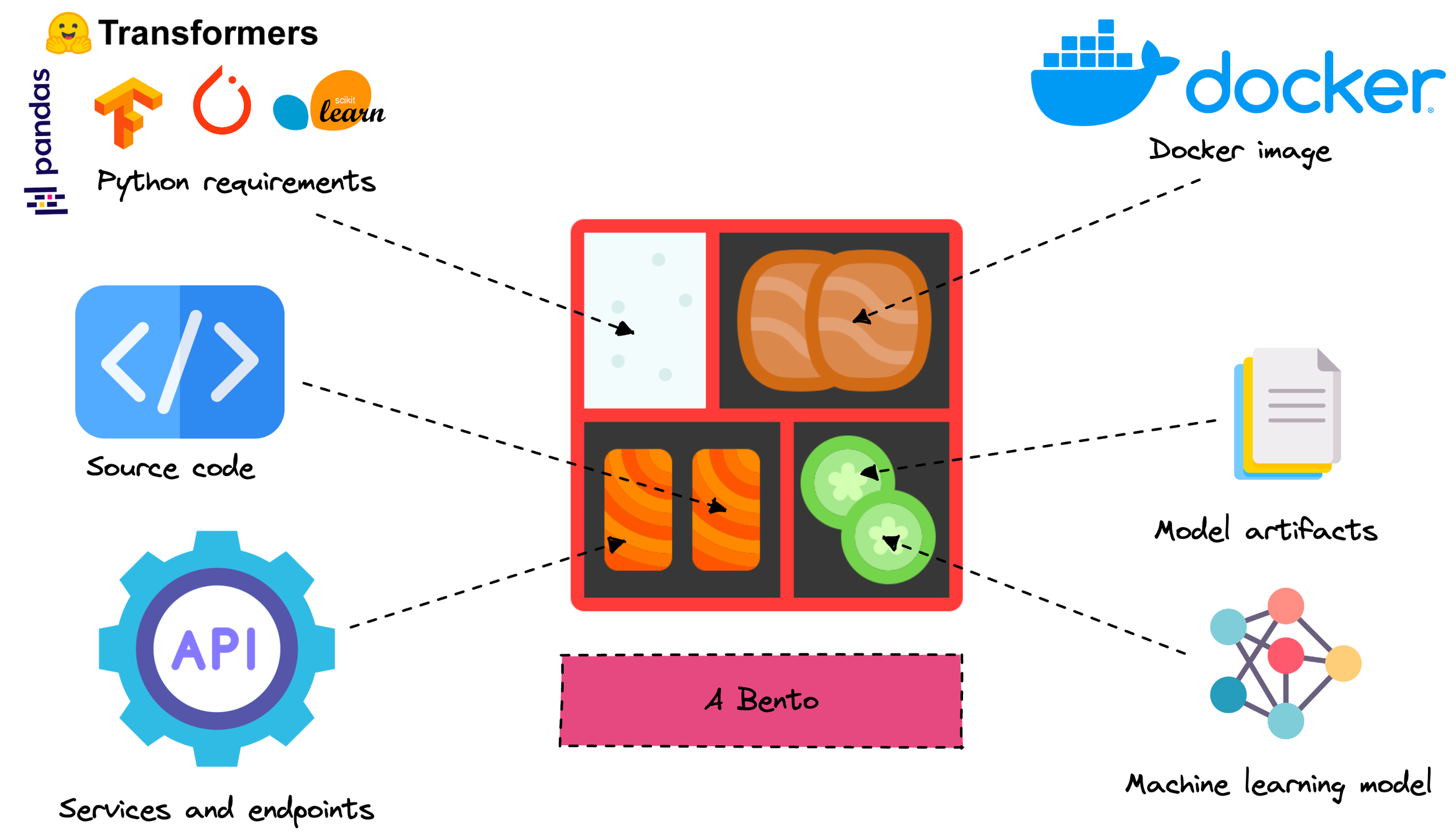
A Bento is Self-contained and
deployable
Everywhere.
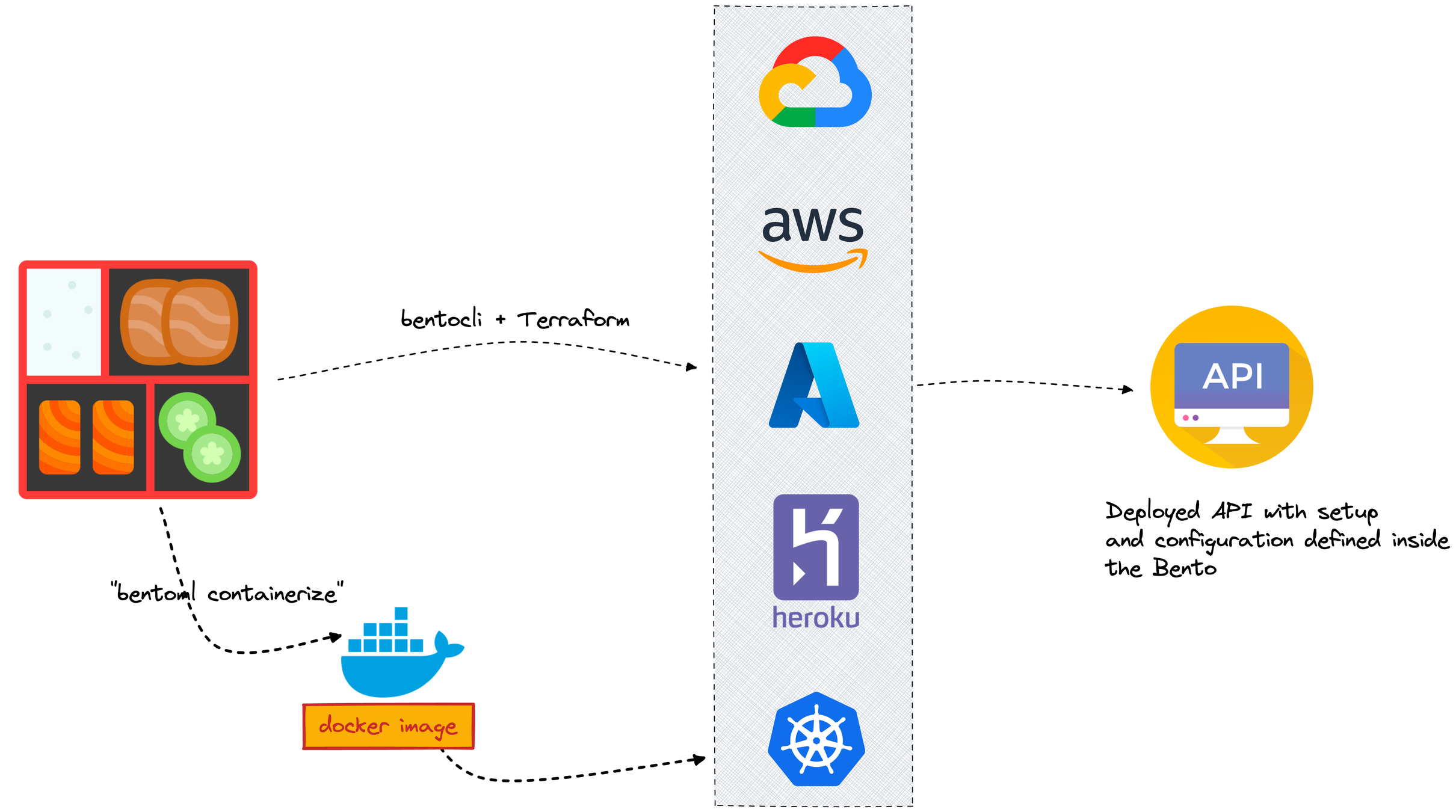
How to save a model with Bento, create an API and deploy it?
Step 1: save a model
import bentoml
from sklearn import svm
from sklearn import datasets
# Load training data set
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Train the model
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
# Save model to the BentoML local model store
saved_model = bentoml.sklearn.save_model("iris_clf", clf)
print(f"Model saved: {saved_model}")
# Model saved: Model(tag="iris_clf:hrcxybszzsm3khqa")
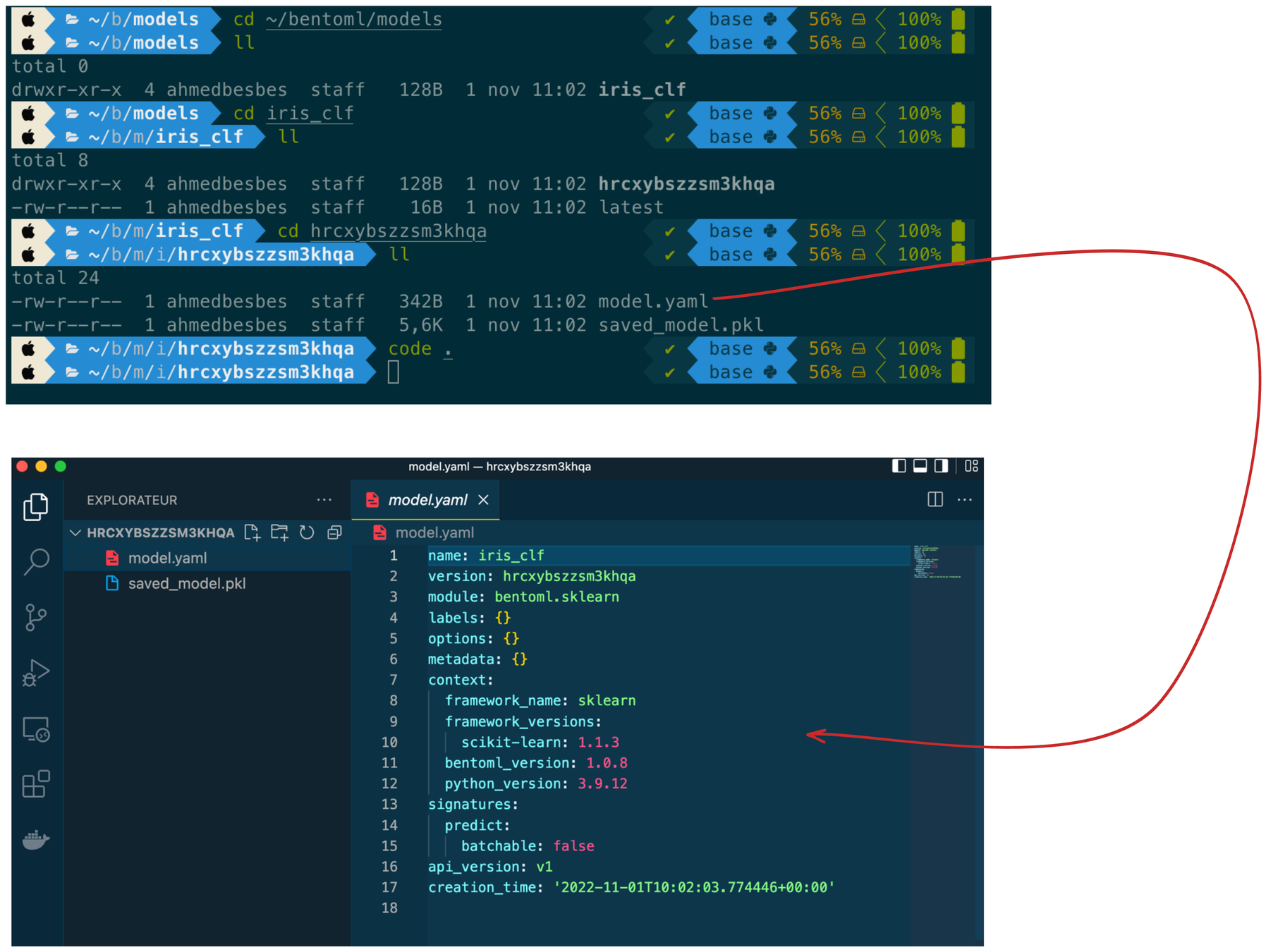
Step 2: Create a service
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
svc = bentoml.Service("iris_classifier", runners=[iris_clf_runner])
@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
result = iris_clf_runner.predict.run(input_series)
return result

import requests
requests.post(
"http://127.0.0.1:3000/classify",
headers={"content-type": "application/json"},
data="[[5.9, 3, 5.1, 1.8]]"
).text
'[2]'

Step 3: build a Bento 🍱
Define a bentofile.yaml
service: "service:svc" # Same as the argument passed to `bentoml serve`
labels:
owner: bentoml-team
stage: dev
include:
- "*.py" # A pattern for matching which files to include in the bento
python:
packages: # Additional pip packages required by the service
- scikit-learn
- pandas
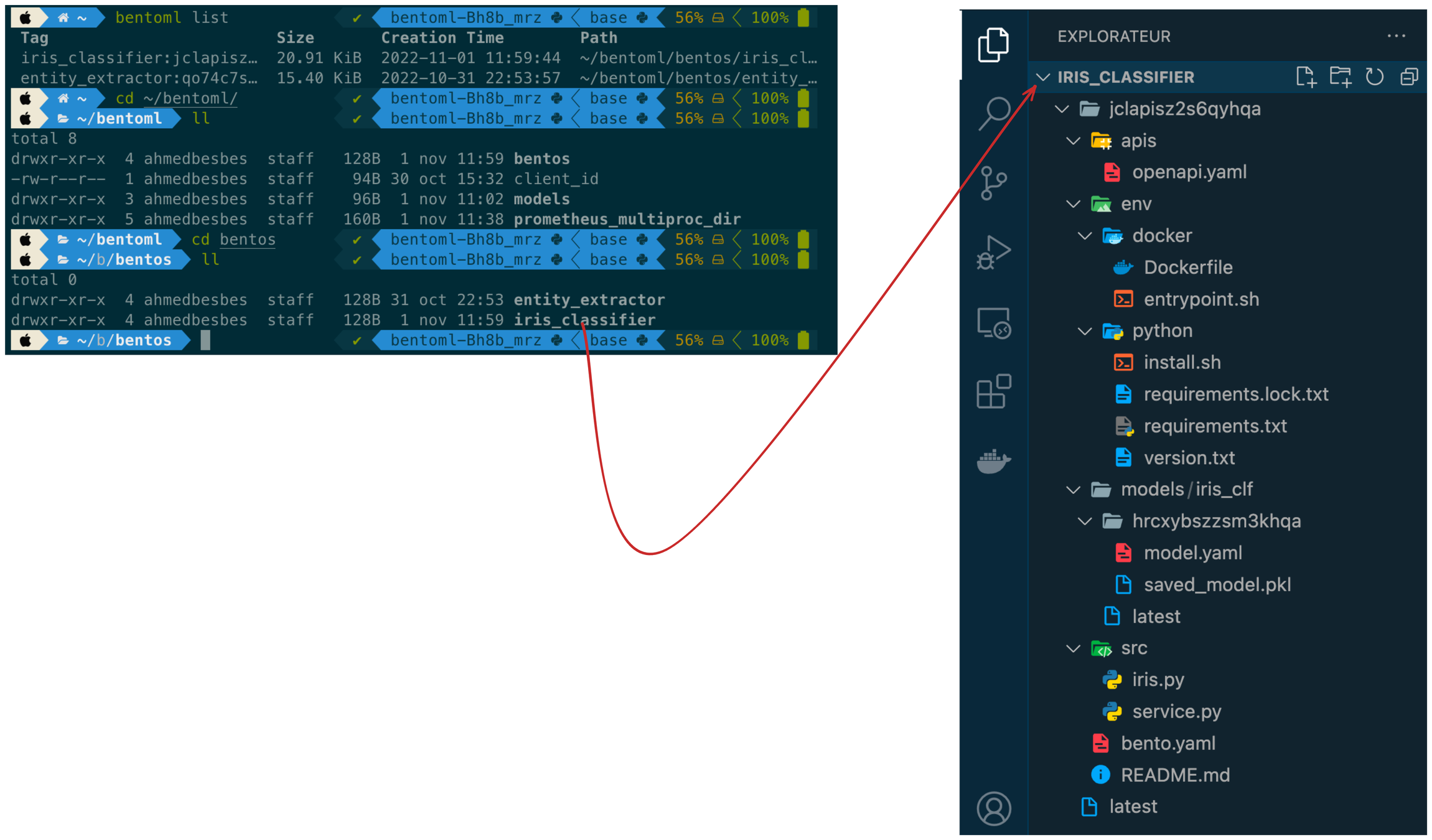
Step 4: containerize
bentoml containerize iris_classifier:latest

docker run -it --rm -p 3000:3000 iris_classifier:jclapisz2s6qyhqa serve --production
Step 5: deploy
3. Super-charged ML features
to make your life easier
1. Micro Batching
Dynamically group prediction requests in real-time into batches for model inference
Increases performance of your app
Increases throughput leverages acceleration hardware
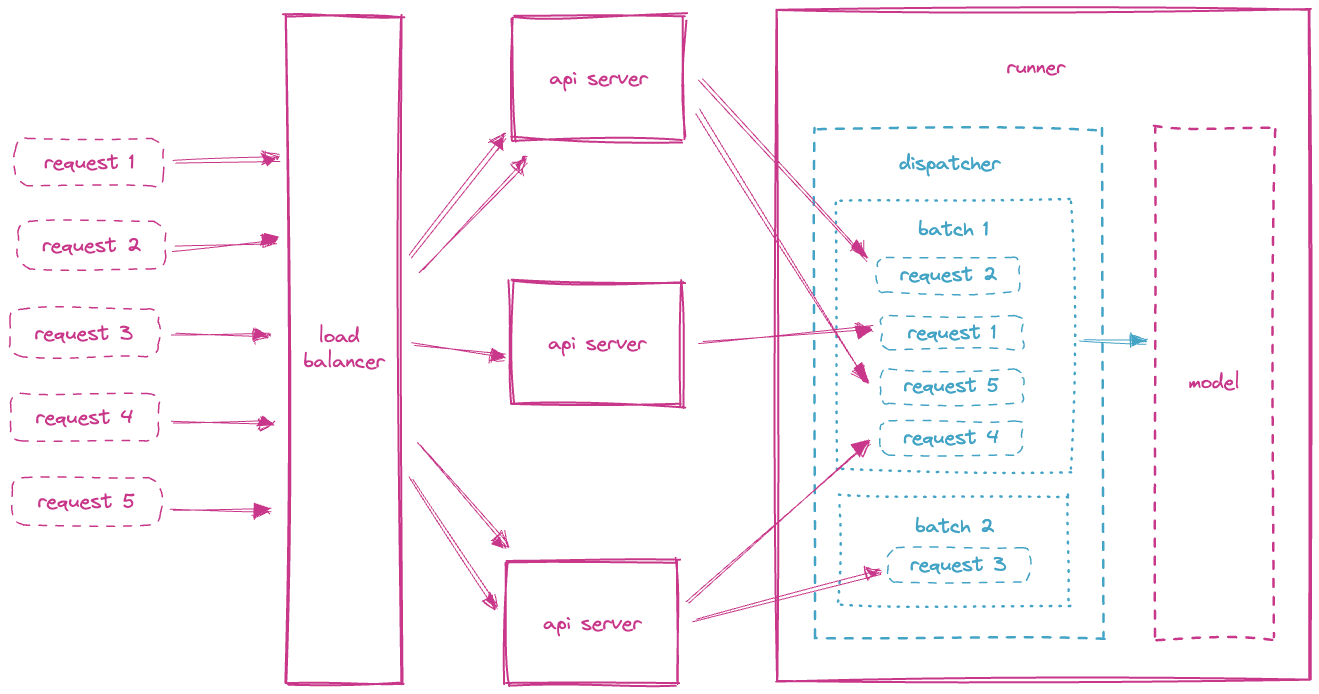
✅ Multiple input requests are run in parallel
✅ A proxy (i.e. a load balancer) distributes requests between workers (a worker is a running instance of an API server)
✅ Each worker distributes the requests to the model runners that are in charge of inference
✅ Each runner dynamically groups the requests in batches by finding a tradeoff between latency and throughput
✅ Runners make predictions on each batch
✅ Batch predictions are then split and released as individual responses
- How to enable batching?
bentoml.pytorch.save_model(
name="mnist",
model=model,
signature={
"__call__": {
"batchable": True,
"batch_dim": (0, 0),
},
},
)send your parallel requests
Bentoml will take care of the rest
2. Parallel inference
Inference graph
Customizable control flows
Combine multiple models

gpt2_generator = (bentoml
.transformers
.get("gpt2-generation:latest").to_runner())
distilgpt2_generator = (bentoml
.transformers
.get("distilgpt2-generation:latest").to_runner())
distilbegpt2_medium_generator = (bentoml
.transformers
.get("gpt2-medium-generation:latest").to_runner())
bert_base_uncased_classifier = (bentoml
.transformers
.get("bert-base-uncased-classification:latest").to_runner())
svc = bentoml.Service(
"inference_graph",
runners=[
gpt2_generator,
distilgpt2_generator,
distilbegpt2_medium_generator,
bert_base_uncased_classifier,
],
)
Load runners
Define service
Define inference workflow
@svc.api(input=Text(), output=JSON())
async def classify_generated_texts(original_sentence: str) -> dict:
generated_sentences = [
result[0]["generated_text"]
for result in await asyncio.gather(
gpt2_generator.async_run(
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
distilgpt2_generator.async_run(
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
distilbegpt2_medium_generator.async_run(
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
)
]
results = []
for sentence in generated_sentences:
score = (await bert_base_uncased_classifier.async_run(sentence))[0]["score"]
results.append(
{
"generated": sentence,
"score": score,
}
)
return results
3. Accelerated runtime
service: "service:svc"
include:
- "*.py"
python:
packages:
- torch
- torchvision
- torchaudio
extra_index_url:
- "https://download.pytorch.org/whl/cu113"
docker:
distro: debian
python_version: "3.8.12"
cuda_version: "11.6.2"
Use GPU and declare it when building the Bento
4. Other cool features
- API Documentation
- Data validation
- gRPC
- Monitoring
https://docs.bentoml.org/en/latest/guides/index.html
3. Demo
4. Resources
to learn more and become a Bento expert
Interesting reads
- https://towardsdatascience.com/comprehensive-guide-to-deploying-any-ml-model-as-apis-with-python-and-aws-lambda-b441d257f1ec
- https://towardsdatascience.com/bentoml-create-an-ml-powered-prediction-service-in-minutes-23d135d6ca76
- https://neptune.ai/blog/ml-model-serving-best-tools
- https://www.reddit.com/r/mlops/comments/w4vl6r/hello_from_bentoml/
- https://docs.bentoml.org/en/latest/concepts/service.html#runners
- https://github.com/bentoml/BentoML/tree/main/examples
- https://modelserving.com/blog/breaking-up-with-flask-amp-fastapi-why-ml-model-serving-requires-a-specialized-framework
[Groupbees] - How to deploy an ML model in production using BentoML
By Ahmed Besbes


