Large Behavior Models
(Foundation models for dexterous manipulation)
Russ Tedrake
MIT, EECS/CSAIL
russt@mit.edu

LLMs \(\Rightarrow\) VLMs \(\Rightarrow\) LBMs
large language models
visually-conditioned language models
large behavior models
\(\sim\) VLA (vision-language-action)
\(\sim\) EFM (embodied foundation model)




Diffusion Policy
ALOHA
Mobile ALOHA
\(\Rightarrow\) Many new startups (some low-cost, some humanoids)
The opportunity
- Common-sense for physical intelligence
- New levels of dexterity (manipulating cloth, liquids, etc)
- Programmed via imprecise natural language and/or a few demonstrations
- "Common-sense robustness"
- GPT might make mistakes, but it always produces beautiful prose...
Q: Is predicting actions fundamentally different?
Why actions (for dexterous manipulation) could be different:
- Actions are continuous (language tokens are discrete)
- Have to obey physics, deal with stochasticity
- Feedback / stability
- ...
should we expect similar generalization / scaling-laws?
Success in (single-task) behavior cloning suggests that these are not blockers
The Robot Data Diet

Big data
Big transfer
Small data
No transfer
robot teleop

(the "transfer learning bet")
Open-X
simulation rollouts


novel devices
We still don't understand the basics
- Clear limitations in current approaches
- some severe context length limitations
- use of proprioception
- ...
- Domain experts give different answers/explanations to basic questions
- Often the answer is "we didn't try that (yet)"
Why we still don't understand the basics
- Have been relying on (small numbers) of hardware rollouts.
- because we don't believe open-loop predictions (~perplexity from LLMs) are predictive of closed-loop,
- and (many) don't believe in sim
- but the experiments are time-consuming and biased
- and the statistical power is very weak
Getting more rigorous



I really like the way Cheng et al reported the initial conditions in the UMI paper.
Rigorous hardware testing
At TRI, we have non-experts run regular "hardware evals"
- Randomized: each rollout randomly selects from multiple policies
- Blind: tester does not know which policy is running
w/ Hadas Kress-Gazit, Naveen Kuppuswamy, ...

Doing proper statistics
- Given:
- i.i.d. Bernoulli samples with unknown probability of success: \(p\),
- user-specified tolerance: \(\alpha\).
- Maximally efficient confidence bounds, \(\underline{p},\overline{p}\), such that:
- e.g., given two policies, run tests until the lower bound of one is above the upper bound of the other.
But "success" is subjective for complex tasks
Example: we asked the robot to make a salad...

simulation-based eval

NVIDIA selected Drake and MuJoCo
(for potential inclusion in Omniverse)
(Establishing faith in)
simulation-based eval
(Establishing faith in)
- Two distinct use cases for sim + BC:
- benchmarking/eval
- data generation (e.g. leveraging privileged info)


TRI's LBM simulation-based eval
- TRI's LBM division is focused on now multitask
- ~15 skills per scene
- Task is not visually obvious, requires language
- 200 demonstrations per skill
Task:
"Bimanual Put Red Bell Pepper in Bin"
Sample rollout from single-skill diffusion policy, trained on sim teleop
Task:
"Bimanual stack plates on table from table"
Sample rollout from single-skill diffusion policy, trained on sim teleop
Example evals during training
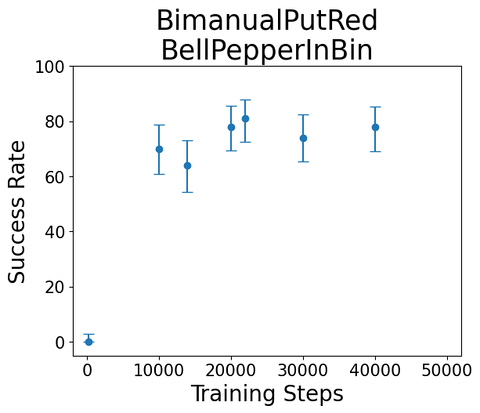
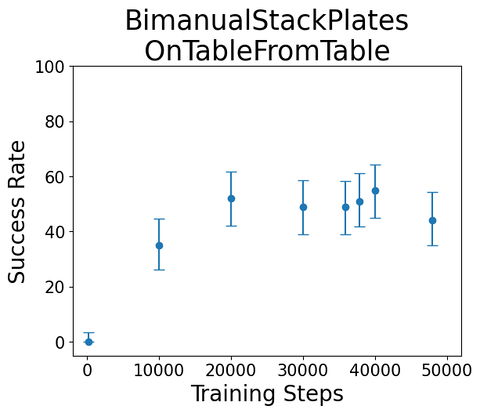
(100 rollouts each, \(\alpha = 0.05\))
The AlphaGo Playbook

- Step 1: Behavior Cloning
- from human expert games
- Step 2: Self-play
- Policy network
- Value network
- Monte Carlo tree search (MCTS)
Studying these fundamentals requires scale
- Unlocked a huge number of basic research questions (both theoretical and experimental)
- MIT has many of the best minds and hands
- need access to compute
- need access to / strategies for scaling data
Online classes (videos + lecture notes + code)
http://manipulation.mit.edu