Towards Large Behavior Models for Dexterous Manipulation
Russ Tedrake
December 15, 2023






Goal: Foundation Models for Manipulation

"Dexterous Manipulation" Team
(founded in 2016)
For the next challenge:
Good control when we don't have useful models?

For the next challenge:
Good control when we don't have useful models?
- Rules out:
- (Multibody) Simulation
- Simulation-based reinforcement learning (RL)
- State estimation / model-based control
- My top choices:
- Learn a dynamics model
- Behavior cloning (imitation learning)
Key advance: visuomotor policies
- The value of using RGB (at control rates) as a sensor is undeniable.
- Policies with (implicit) learned state representations
- I don't love imitation learning (decision making \(\gg\) mimcry), but it's an awfully clever way to explore the space of policy representations
- Don't need a model
- Don't need an explicit state representation
- (Not even to specify the objective!)
We've been exploring, and found something good in...

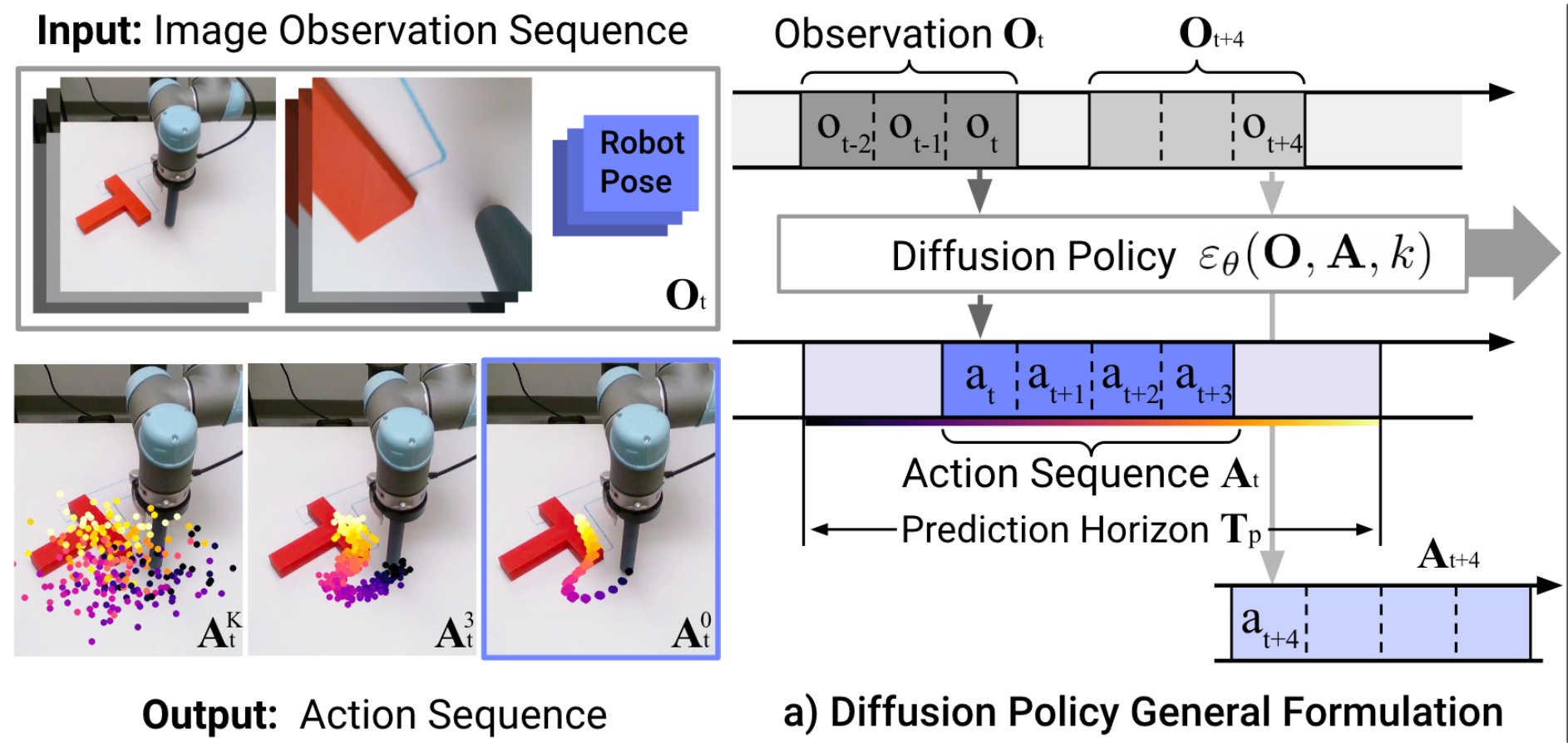
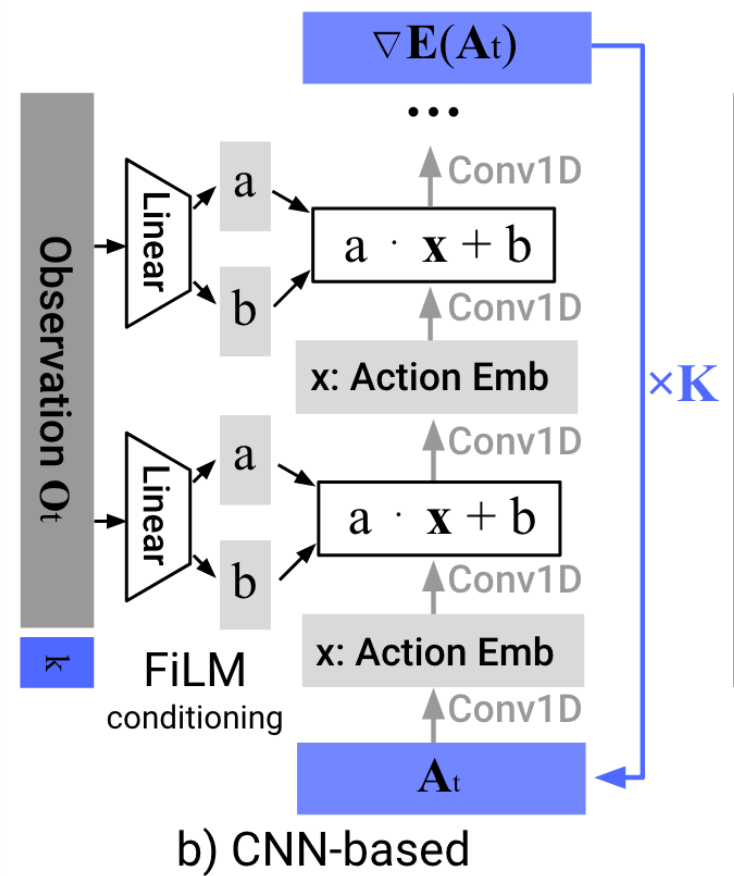
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
(Often) Reactive
Discrete/branching logic
Long horizon
Limited "Generalization"
(when training a single skill)
But there are definitely limits to the single-task models
Why (Denoising) Diffusion Models?
- High capacity + great performance
- Small number of demonstrations (typically ~50-100)
- Multi-modal (non-expert) demonstrations

Learns a distribution (score function) over actions
e.g. to deal with "multi-modal demonstrations"

Why (Denoising) Diffusion Models?
- High capacity + great performance
- Small number of demonstrations (typically ~50)
- Multi-modal (non-expert) demonstrations
- Training stability and consistency
- no hyper-parameter tuning
- Generates high-dimension continuous outputs
- vs categorical distributions (e.g. RT-1, RT-2)
- CVAE in "action-chunking transformers" (ACT)
- Solid mathematical foundations (score functions)
- Reduces nicely to the simple cases (e.g. LQG / Youla)
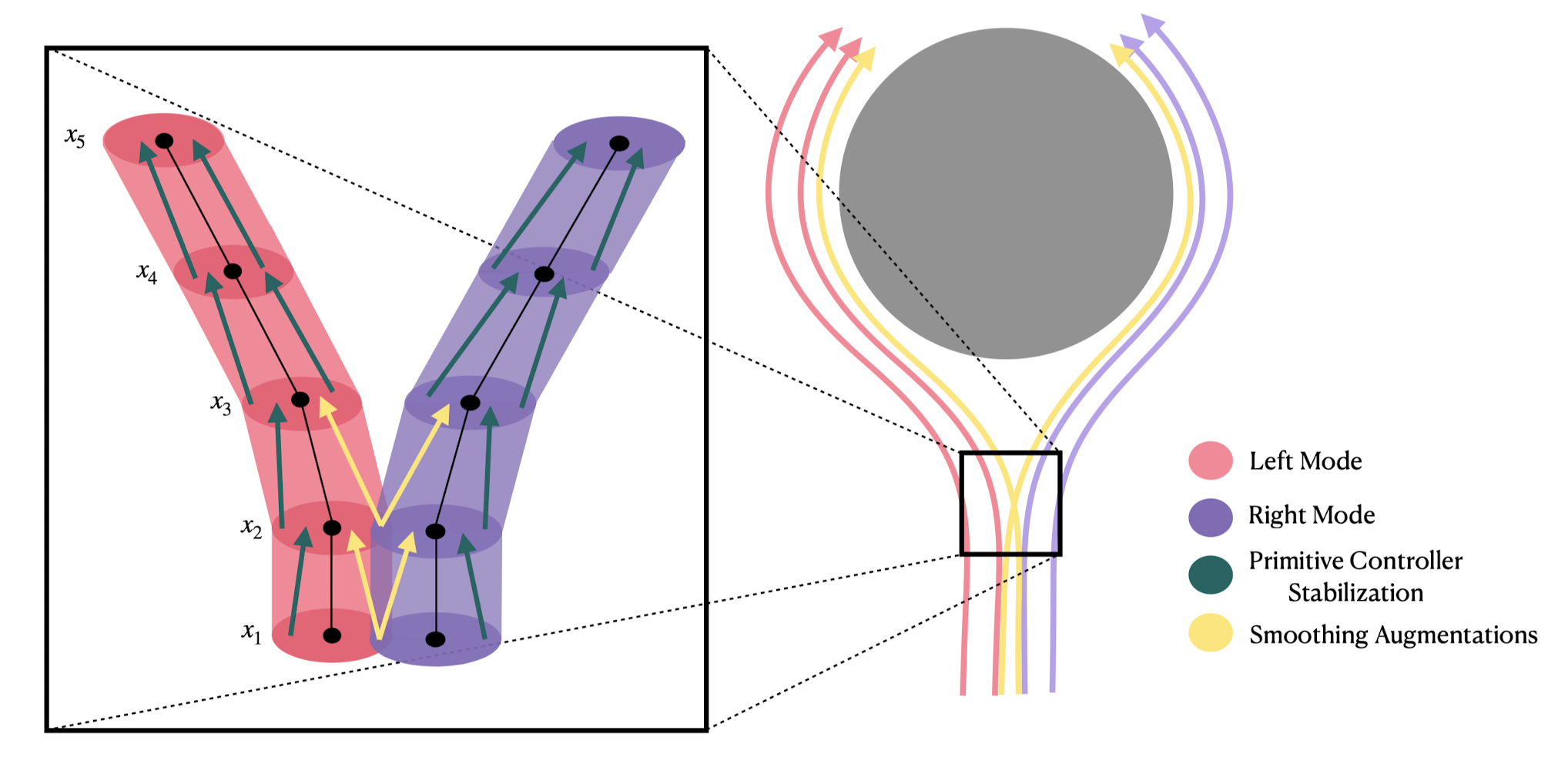
Denoising LQR ( )
Standard LQR:
Optimal actor:
Training loss:
stationary distribution of optimal policy
Optimal denoiser:
(deterministic) DDIM sampler:
Straight-forward extension to LQG:
Diffusion Policy learns (truncated) unrolled Kalman filter.
converges to LQR solution
Denoising LQR ( )
Enabling technologies
Haptic Teleop Interface
Excellent system identification / robot control
Visuotactile sensing

with TRI's Soft Bubble Gripper
Open source:
Scaling Up
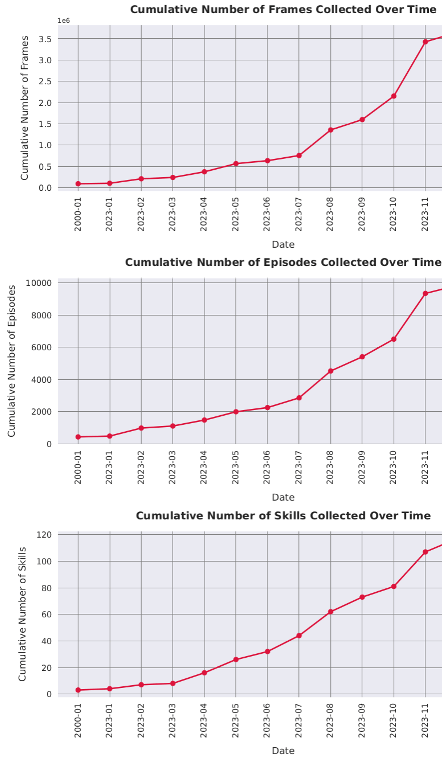
Cumulative Number of Skills Collected Over Time
Earlier this week...
- Today's focus: training one skill
-
Multitask, language-conditioned policies
-
multitask training can improve robustness of original skills
- partly by consuming more data
- few shot generalization to new skills
-
multitask training can improve robustness of original skills
-
Big Questions:
- How do we feed the data flywheel? What's the right data?
- What are the scaling laws?
- Benchmarking/evaluation
TRI's role in this push
- High-quality datasets
- of dynamically rich demonstrations
- leveraging our robotics+control expertise + ML expertise
- high-fidelity simulation for evaluation / scaling / benchmarking

Discussion
I do think there is something deep happening here...
- Manipulation should be easy (from a controls perspective)
- probably low dimensional?? (manifold hypothesis)
- memorization can go a long way
Model-based control and structured optimization
Graphs of Convex Sets
for trajectory optimization and RL
Online classes (videos + lecture notes + code)
http://manipulation.mit.edu
http://underactuated.mit.edu

Dexterous Manipulation at TRI
https://www.tri.global/careers