Visuomotor Policies
(via Behavior Cloning)

MIT 6.421:
Robotic Manipulation
Fall 2023, Lecture 18
Follow live at https://slides.com/d/0Oepxvs/live
(or later at https://slides.com/russtedrake/fall23-lec18)

policy needs to know
state of the robot x state of the environment
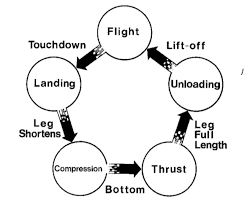
The MIT Leg Lab Hopping Robots

http://www.ai.mit.edu/projects/leglab/robots/robots.html
What is a (dynamic) model?
System
State-space
Auto-regressive (eg. ARMAX)
input
output
state
noise/disturbances
parameters



2017
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
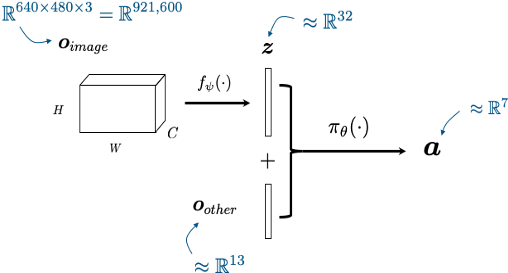
Visuomotor policies
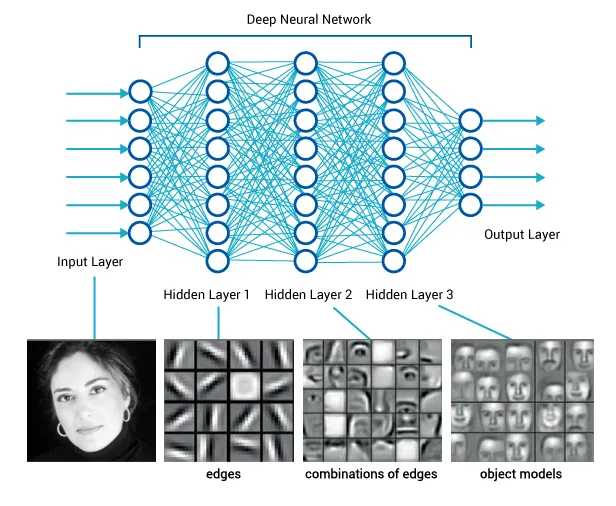
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history
Idea: Use small set of dense descriptors
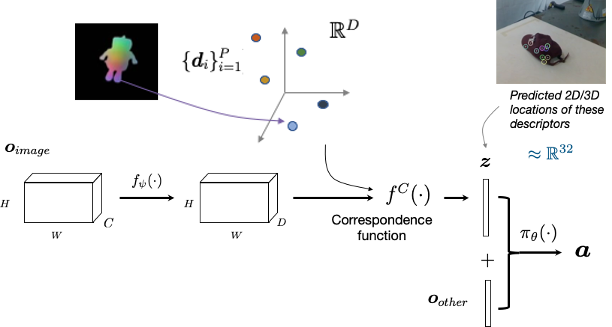
Imitation learning setup
from hand-coded policies in sim
and teleop on the real robot
Standard "behavior-cloning" objective + data augmentation
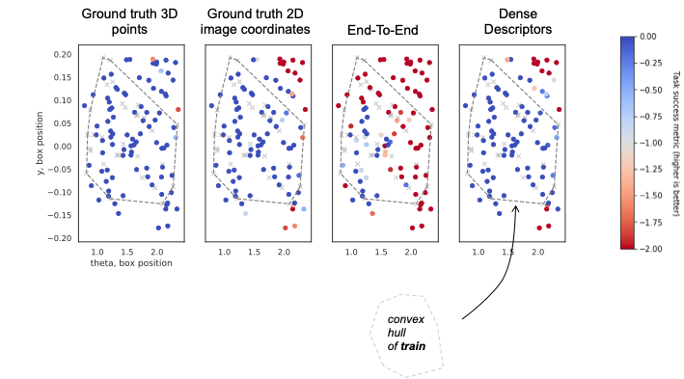
Simulation experiments
"push box"
"flip box"
Policy is a small LSTM network (~100 LSTMs)
I was forced to reflect on my core beliefs...
- The value of using RGB (at control rates) as a sensor is undeniable. I must not ignore this going forward.
- I don't love imitation learning (decision making \(\gg\) mimcry), but it's an awfully clever way to explore the space of policy representations
- Don't need a model
- Don't need an explicit state representation
- (Not even to specify the objective!)
"And then … BC methods started to get good. Really good. So good that our best manipulation system today mostly uses BC, with a sprinkle of Q learning on top to perform high-level action selection. Today, less than 20% of our research investments is on RL, and the research runway for BC-based methods feels more robust."


From last week...
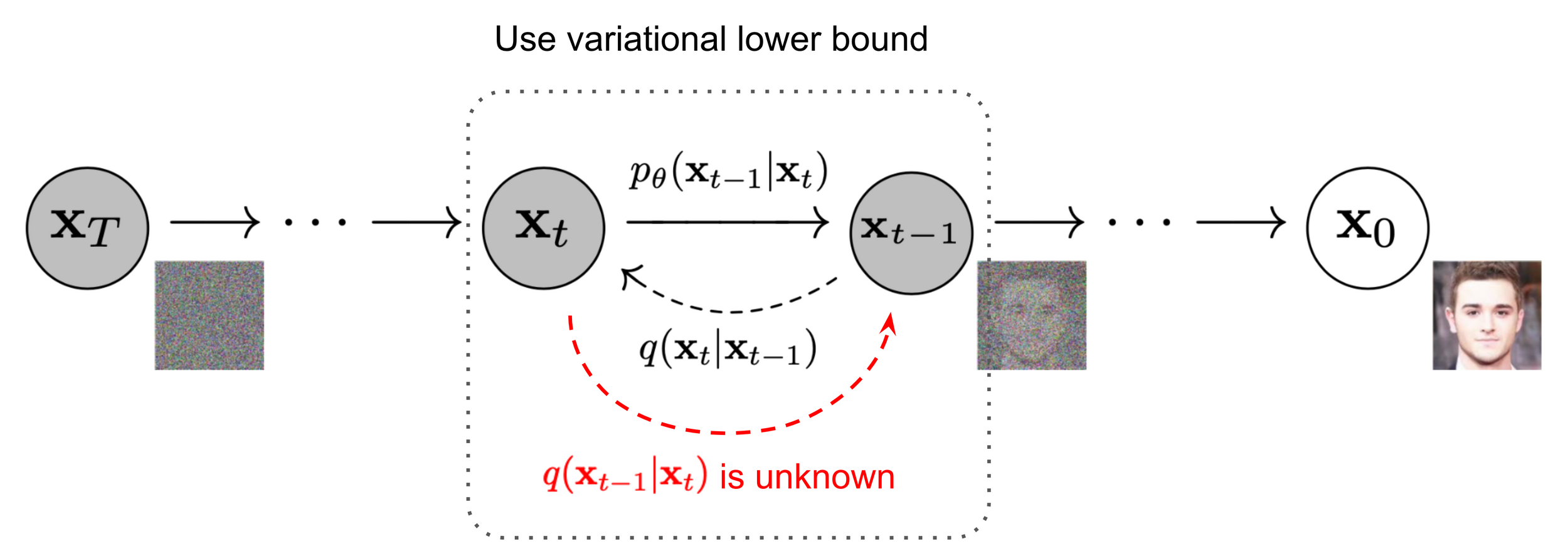
Denoising diffusion models (generative AI)
Image source: Ho et al. 2020
Denoiser can be conditioned on additional inputs, \(u\): \(p_\theta(x_{t-1} | x_t, u) \)
A derministic interpretation (manifold hypothesis)

Denoising approximates the projection onto the data manifold;
approximating the gradient of the distance to the manifold
Representing dynamic output feedback
input
output
Control Policy
(as a dynamical system)
"Diffusion Policy" is an auto-regressive (ARX) model with forecasting
\(H\) is the length of the history,
\(P\) is the length of the prediction
Conditional denoiser produces the forecast, conditional on the history
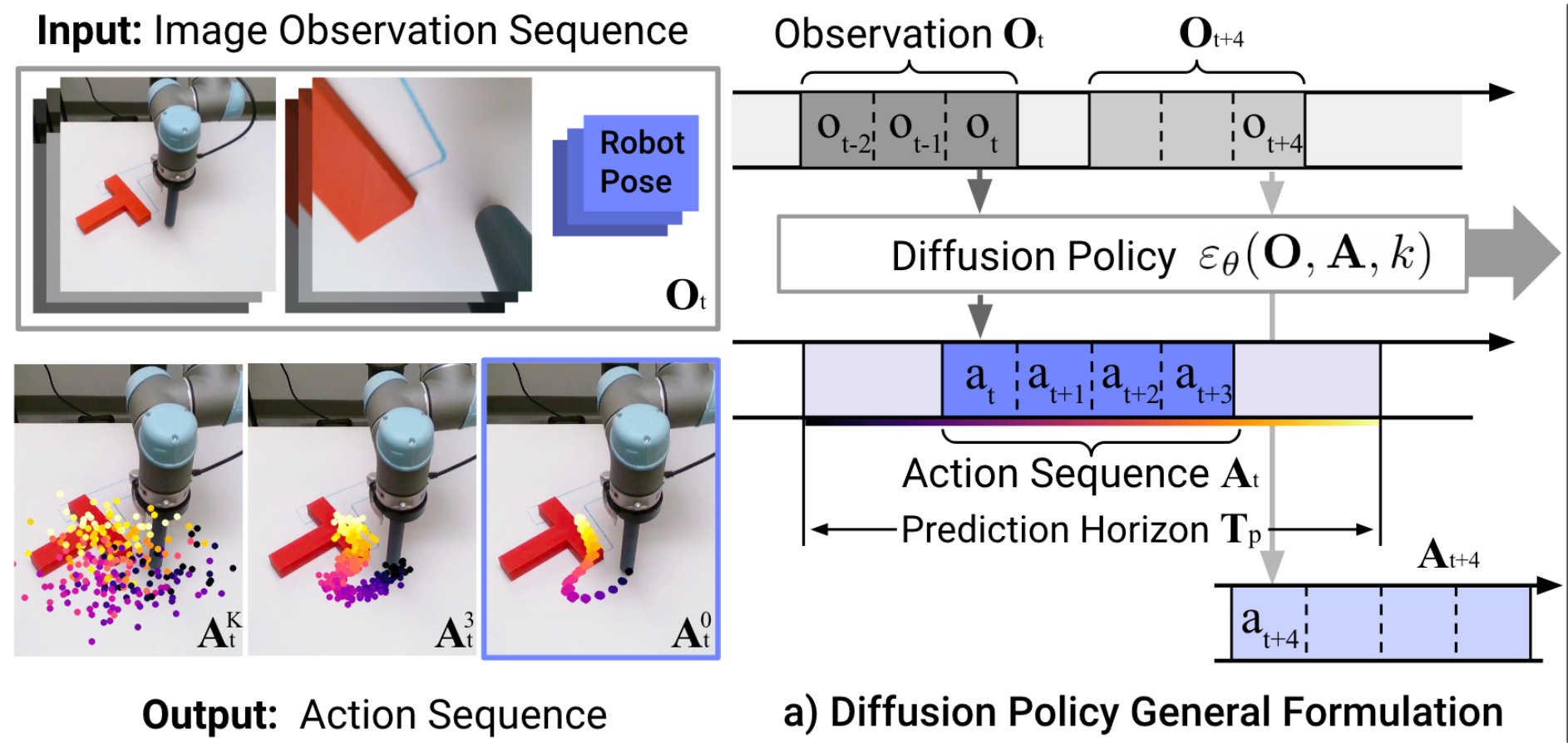
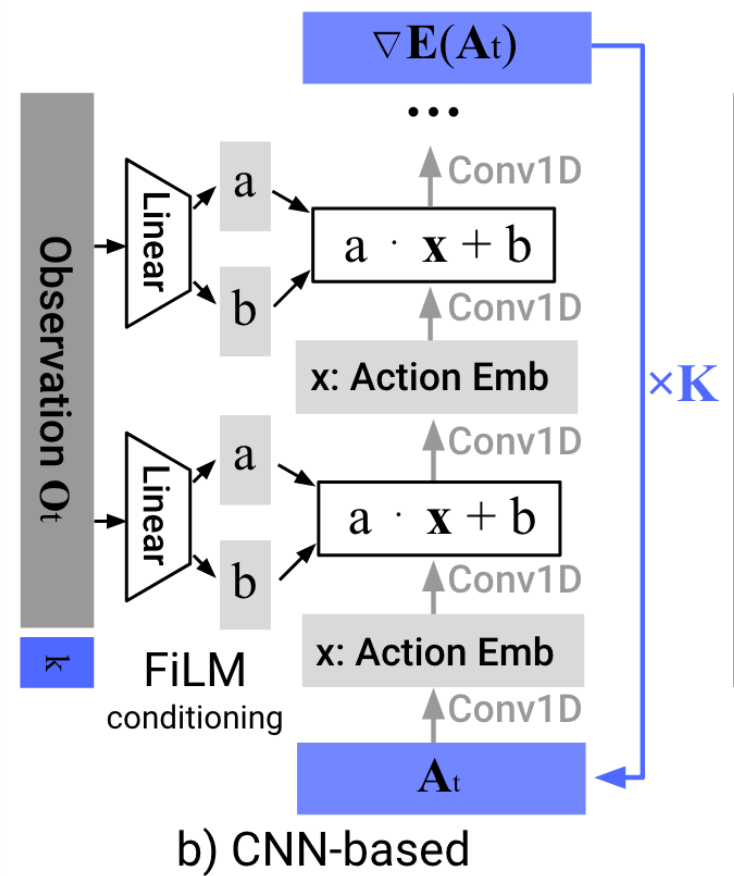
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)

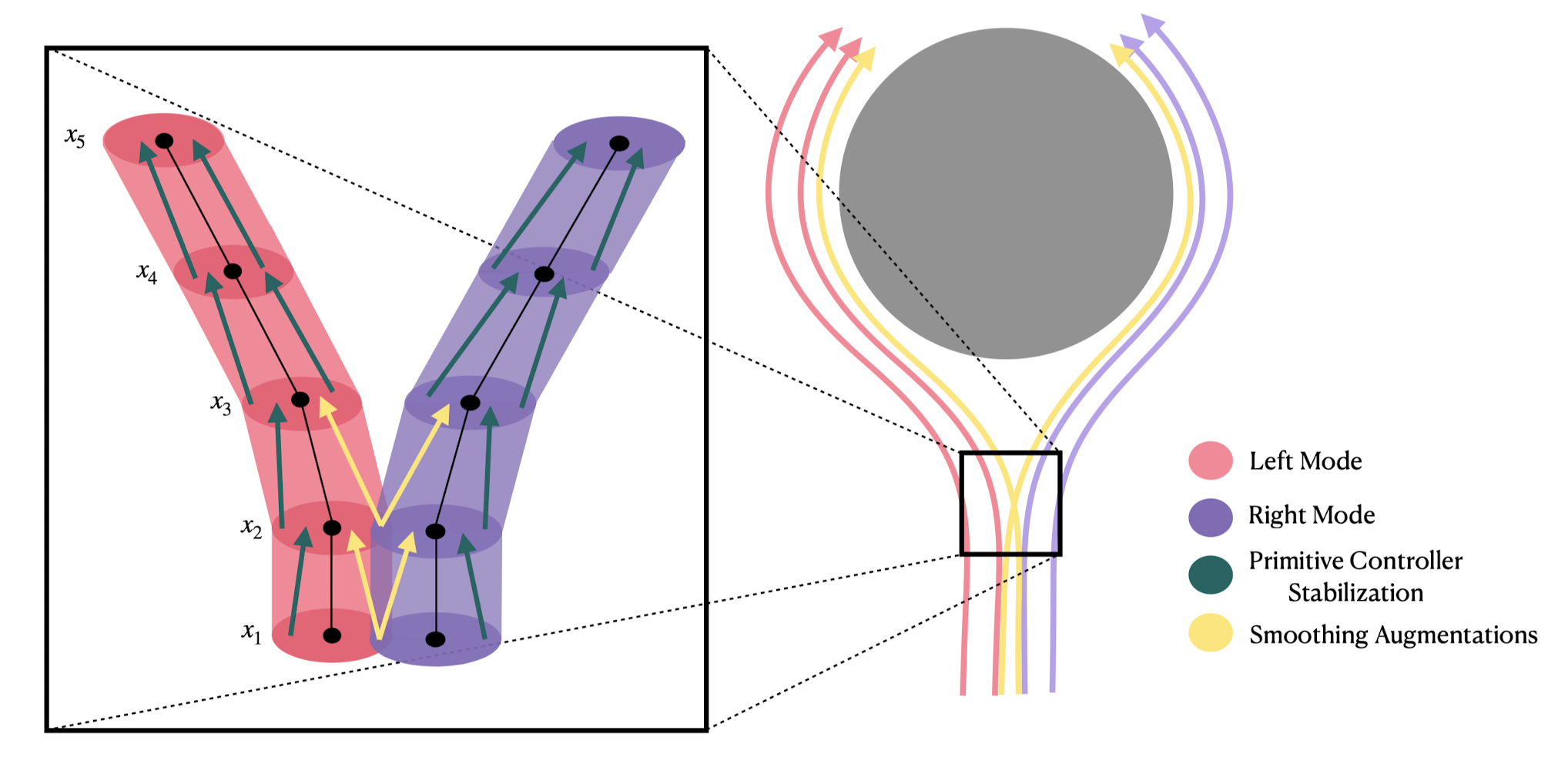
Learns a distribution (score function) over actions
e.g. to deal with "multi-modal demonstrations"


Andy Zeng's MIT CSL Seminar, April 4, 2022

Andy's slides.com presentation
Why (Denoising) Diffusion Models?
- High capacity + great performance
- Small number of demonstrations (typically ~50)
- Multi-modal (non-expert) demonstrations
- Training stability and consistency
- no hyper-parameter tuning
- Generates high-dimension continuous outputs
- vs categorical distributions (e.g. RT-1, RT-2)
- Action-chunking transformers (ACT)
- Solid mathematical foundations (score functions)
- Reduces nicely to the simple cases (e.g. LQG / Youla)
Enabling technologies
Haptic Teleop Interface
Excellent system identification / robot control
Visuotactile sensing

with TRI's Soft Bubble Gripper
Open source:
Scaling Up
- I've discussed training one skill
-
Wanted: few shot generalization to new skills
- multitask, language-conditioned policies
- connects beautifully to internet-scale data
-
Big Questions:
- How do we feed the data flywheel?
- What are the scaling laws?
- I don't see any immediate ceiling